 Подписаться
Подписаться Читать в телеграм
Читать в телеграм3500 объектов инфраструктуры: Как сеть «Вкусно — и точка» настроила мониторинг за 10 месяцев
Дата публикации:
21.10.2024
Посетителей:
64
Просмотров:
63
Время просмотра:
2.3

№4 (320) / 2024
№4 (320) / 2024
Впечатления от внедрения системы мониторинга ИТ-инфраструктуры можно передать тремя словами: безопасно, комплексно, надежно. Об особенностях реализации проекта и сложностях работы в огромной компании, а также о планах на будущее рассказал Станислав Моргаев, специалист по мониторингу информационных систем.
— Станислав, какие задачи вы ставили при внедрении системы мониторинга ИТ-инфраструктуры в компании «Вкусно — и точка», особенно с учетом перехода от McDonald’s? Были какие-то «наследственные болезни»?
С уходом предыдущей компании из России, ушел и огромный пласт технологических решений. В нашем распоряжении остались только локальная инфраструктура и локальные ИТ-сервисы, критически необходимые для бизнеса. Все остальные решения, в том числе ITSM, мониторинг и даже корпоративный портал, «помахали ручкой». Поэтому меня и пригласили поднимать с нуля систему мониторинга и задействовать ее как в текущей инфраструктуре компании, которая обеспечивает бизнес, так и в новых решениях, которые внедряются для нормализации и стабилизации бизнес-процессов.
— Что вы имеете в виду, говоря «с нуля»? У компании вообще не было решений в части мониторинга или просто все они исчезли в один момент?
Остались какие-то архаичные локальные решения для мониторинга, но их функционал был минимальным, а версии — совсем устаревшими. Мы поняли, что поддерживать и развивать их дальше нет смысла. Поэтому сейчас мы делаем с нуля красивую, отказоустойчивую, современную систему мониторинга. – Когда вы приступили к ее развертыванию? Я пришел в компанию в апреле 2023 г. Примерно полгода мы занимались организацией рабочих процессов, согласованием и тендерными процедурами, после чего начали предпроект развертывания системы на новой инфраструктуре. Активно покрывать мониторингом инфраструктуры и критичные бизнес-приложения компании мы начали в марте этого года, а сейчас завершаем проект внедрения.
— Какой объем инфраструктуры был покрыт мониторингом в рамках проекта?
За 10 месяцев реализации мониторинг был настроен для
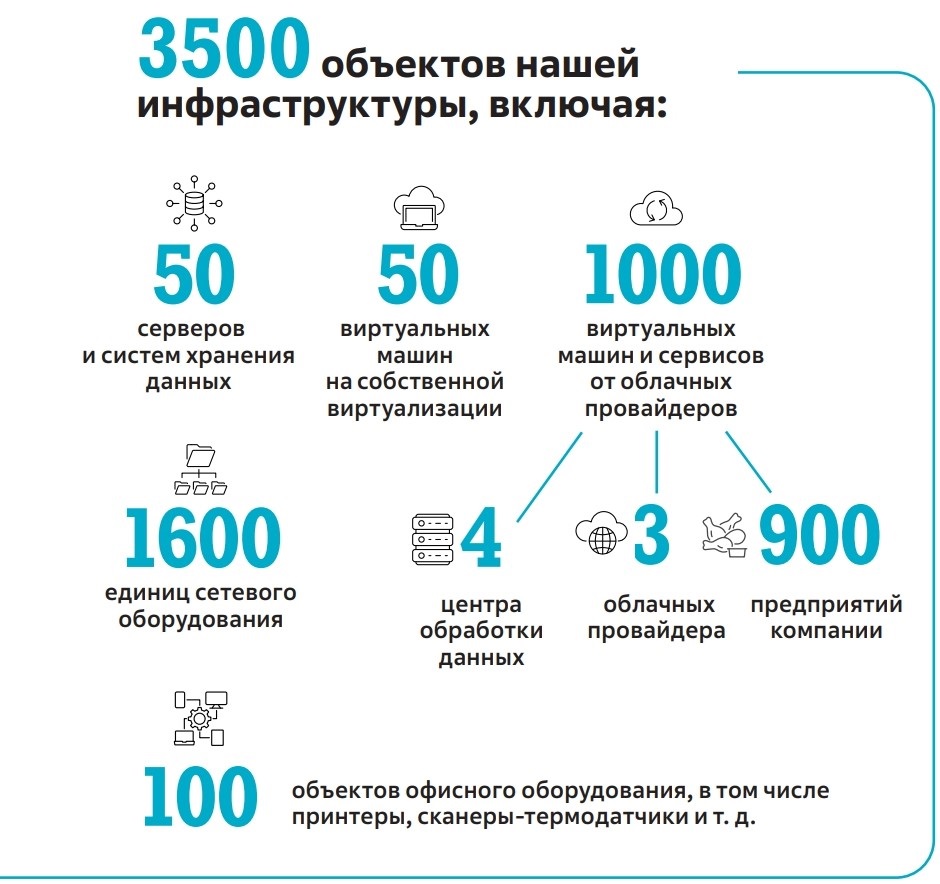
— На решениях каких вендоров строилась новая система мониторинга?
У нас довольно классический стек, потому что было необходимо покрыть хотя и архаичные, но важные для работы компании приложения. Однако при этом требовалось двигаться в будущее с новыми решениями. Используем продукты open source: Zabbix, Grafana, Prometheus и Graylog. И над ними, для более красивой визуализации и устранения слабых мест Zabbix, добавляем зонтик — решение Monq.
— Ставилась ли перед вами задача по максимуму использовать решения и продукты отечественных вендоров?
Нет, такая задача не стояла. Мы ориентируемся на «ванильный» open source, а если нет другого выбора, то используем решения, сертифицированные Минцифры.
— С учетом масштаба и формата сети «Вкусно — и точка», какие критерии стали для вас ключевыми при выборе конкретных решений по мониторингу ИТ-инфраструктуры?
На самом деле каких-то жестких и строгих критериев мы не ставили. До этого я уже работал в корпорации с похожим объемом инфраструктуры и похожей разветвленностью по геолокации. Поэтому с технологическим стеком мук выбора не было. Нам требовалось решить главную задачу — получить на выходе единую отказоустойчивую систему мониторинга, которая могла бы легко взаимодействовать с другими системами компании.
— С какими сложностями вы столкнулись при интеграции новой системы мониторинга в инфраструктуру?
Часть нашей инфраструктуры живет у cloud-провайдеров. И их документация по мониторингу, как правило, не актуальна, что вызывает множество трудностей — вплоть до необходимости переделывать всю предыдущую работу, если в ее реализации мы ориентировались на неверные вводные. Но нам удалось справиться с этим, и сейчас все облачные сервисы и все виртуальные машины покрыты мониторингом и при этом автоматически обнаруживаются с помощью их API. Кроме того, при обновлении Monq мы выявили множество багов, которые приходилось устранять буквально на лету. Впрочем, этого можно было бы легко избежать при наличии у нас тестового контура, где можно экспериментировать с обновлениями до их финальной установки. Конечно, в процессе были и другие затруднения, но говорить о них я не буду.
— Какие ключевые особенности инфраструктуры сети «Вкусно — и точка» вы можете отметить?
Вся специфика состоит в том, что инфраструктура компании объемная сама по себе. В ней много оборудования и конфигурационных единиц, они распределены по всей территории РФ. Но архитектура решения и процесс внедрения были не очень сложными — просто трудоемкими.
— А есть инфраструктурные различия между вашим головным офисом и самими предприятиями?
Для офиса используется стандартная инфраструктура, при этом он выступает одним из наших ЦОД. А предприятия — это просто удаленные локации, в которых тоже есть оборудование, но оно работает по большей части автономно. Существует связь предприятий с офисом, но для обеспечения работы она не должна поддерживаться в непрерывном режиме.
— Вы обмолвились о том, что для вас это первый опыт реализации проекта такого масштаба. Как в компании выстраивается работа с командой? Как осуществляются обучение и поддержка сотрудников в работе с новой системой мониторинга?
В этом плане все просто: мы внедряли решение с помощью команды подрядчика, а я выступал в качестве ИТ-руководителя со стороны заказчика. Команда подрядчика состояла из трех человек. Это очень опытные, сильные специалисты по мониторингу из компании «Инфосистемы Джет». То есть мне не пришлось никого самому искать или обучать с нуля — у меня сразу под рукой был сплоченный коллектив профессионалов, которые и так отлично знали свою работу. Поэтому за последние полгода активной работы мы покрыли мониторингом инфраструктуру и все наши критичные бизнес-приложения.

— Сейчас проект находится на финишной прямой. Какие выводы на будущее уже можно сделать? На что нужно обращать внимание в первую очередь и как в принципе выстраивать работу с такими масштабными задачами?
На мой взгляд, самое важное — это находиться на одной волне с линейными руководителями и топ-менеджерами компании, понимать их запросы и видеть горизонты будущего развития. В рамках проекта мы пока не покрыли системой мониторинга все, что есть в сети «Вкусно — и точка». В частности, мы еще подробно не заходили с мониторингом на наши предприятия, которых насчитывается более 900 по всей стране. Неохваченными остаются и множество второстепенных бизнес-приложений, которые также используются в компании. Это объясняется более низким приоритетом задачи по организации их мониторинга и ограниченностью ресурсов, которые можно задействовать при ее выполнении. Поэтому у нас большой фронт работы на будущее.
Еще я бы посоветовал руководителям ИТ-инфраструктуры не пренебрегать тестовым контуром для приложений. Это особенно актуально для работы с российскими решениями, поскольку, к сожалению, они часто не достигают высокого уровня зрелости и требуют тщательного тестирования перед внедрением и установкой обновлений.
— У команды есть планы по дальнейшему развитию и масштабированию системы мониторинга ИТ-инфраструктуры?
Выработанные ранее подходы мы будем использовать и в отношении других ИТ-сервисов, на которые также будет распространяться мониторинг. В ходе этой работы распределим зоны ответственности, поймем, какая часть инфраструктуры на какие процессы влияет, все структурируем и визуализируем в виде красивых ресурсно-сервисных моделей — с конкретными ответственными сотрудниками и понятными сроками реагирования. Надеюсь, что уже в 2025 г. на всех предприятиях сети «Вкусно — и точка» будет реализован качественный мониторинг.
Первая часть предлагаемой статьи содержит обобщение шестилетнего опыта компании "Инфосистемы Джет" в сфере построения систем диагностики (мониторинга) заказных приложений.
Как выбрать подрядчика в изменившихся условиях российского рынка? Чем руководствоваться при минимизации рисков? ИТ-риски не пройдут: к каким последствиям могут привести сбои в работе сервисной команды?
На сегодняшний день большинство компаний в России, использующих ИТ-технологии в своей работе, применяет сервисный подход к управлению ИТ-инфраструктурой и прикладными системами.
Операционный директор продуктовой студии AXEL PRO рассказал, как его команда добивается признания на рынке, объединяет разработку инновационных решений и поддержку стартапов в сфере кибербезопасности.
Сегодня инструменты мониторинга приложений, предоставляемые по модели SaaS (есть даже термин MaaS, Monitoring As A Service), не очень востребованы крупными и средними российскими компаниями
Операционный директор продуктовой студии AXEL PRO рассказал, как его команда добивается признания на рынке, объединяет разработку инновационных решений и поддержку стартапов в сфере кибербезопасности.
Что сайзинг дает бизнесу? С чего начать и как избежать типовых проблем? Советы от «Инфосистемы Джет».
Коммутатор Edge-Core можно превратить в АТС либо использовать его для установки Zapex-сервера — чтобы организовать мониторинг работы оборудования на площадке. Новый способ размещения контейнера позволит сократить номенклатуру оборудования, устанавливаемого в небольших удаленных филиалах или точках продаж (например, на автозаправках и газовых станциях). Прямые аналоги использования подобных решений с White Box в российской и зарубежной практике пока неизвестны.
Отсутствие импортных модулей в SpaceVM гарантирует высокий уровень ИБ. Технология FreeGRID обеспечивает работу с лицензионными продуктами NVIDIA и исключает их возможную блокировку. Проприетарный контроллер SpaceVM открывает широкие возможности для кастомизации.

Мы всегда рады ответить на любые Ваши вопросы
Благодарим за обращение. Ваша заявка принята
Наш специалист свяжется с Вами в течение рабочего дня


