 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
В первую очередь, возросло число генераторов данных, причем весьма большого объема – это Web 2.0 системы, а именно социальные сети разных видов, данные электронной почты, Twitter, Wiki-проекты. Кроме того, огромные объемы данных могут генерироваться датчиками различных типов – Сall Data Records (CDR) сотовых операторов, телеметрические данные, информация с камер видеонаблюдения и т.п. Во-вторых, значительное уменьшение стоимости хранения привело к тому, что многие компании могут позволить себе следовать парадигме «данные слишком ценны, чтобы их уничтожать».
Но главная проблема заключается в том, что кроме количества данных изменился и их характер. Основной объем этих данных – неструктурированная информация, поэтому ее хранение и обработка в привычных системах на основе реляционных БД, как правило, малоэффективна. И постепенно пришло осознание того, что реляционные СУБД не являются оптимальным решением для ряда ситуаций, а это, в свою очередь, привело к появлению целого семейства решений, которые можно классифицировать одним словом – NoSQL- системы.
Рис. 1. Работа данных в rDBMS-системе 
Термин NoSQL расшифровывается как Not Only SQL (не только SQL). На сегодняшний момент существует большое количество таких систем, но все они, как правило, обладают следующими характеристиками:
- гибкость использования: у подобных систем отсутствуют требования к наличию схемы данных, а в качестве модели хранения выступает JSON1;
- встроенные возможности горизонтального масштабирования и параллельной обработки;
- возможность быстрого получения первых результатов.
Сравним типичный сценарий работы с данными в RDBMS (Relational Database Management System, реляционная СУБД) и в NoSQL-системе. В случае с RDBMS необходимо разработать схему хранения данных. Кроме того, перед загрузкой в СУБД данные должны быть очищены и преобразованы в требуемые форматы, только после этого ими можно будет воспользоваться через язык SQL-запросов. Таким образом, необходимо пройти как минимум шесть этапов (причем трансформация и загрузка данных могут быть весьма длительными и трудоемкими процессами), прежде чем появятся первые результаты (см. рис. 1).
Рис. 2. Работа данных в noSqL-системе 
В случае с NoSQL ситуация выглядит значительно проще: после поступления данных в хранилище система уже готова к работе, конечно, при условии что у вас есть готовая программа обработки (см. рис. 2).
Все NoSQL-системы при всем их многообразии можно разделить на два больших класса. Во-первых, это различные виды NoSQL Key/Value Database, или NoSQL базы данных. Типичными представителями этого класса систем являются такие проекты, как MongoDB, Cassandra или HBase. Все они представляют собой разновидность баз данных, хранящих информацию в виде пар «ключ–значение» и не имеющих жесткой схемы данных. Как правило, подобные продукты горизонтально масштабируются (объединяются в кластер из однотипных недорогих узлов) и имеют встроенные средства защиты от выхода из строя отдельных компонент
кластера. Их удобно использовать в условиях постоянно изменяющейся (или вообще неопределенной) структуры данных.
Постепенно пришло осознание того, что реляционные СУБД не являются оптимальным решением для ряда ситуаций, а это привело к появлению семейства решений, которые можно классифицировать одним словом – NoSQL-системы
Например, БД NoSQL часто используют для сбора и хранения информации в социальных сетях. Поскольку приложения, с которыми работают пользователи, очень быстро меняются, структуру данных делают максимально простой: вместо того чтобы разрабатывать схему данных со связями между сущностями, создают структуры, содержащие основной ключ для идентификации данных и привязанное к нему содержимое. Такие оптимизированные и динамические структуры позволяют проводить изменения, не выполняя сложную и дорогую реорганизацию на уровне хранилища.
Более подробно о базах данных NoSQL и особенностях работы с ними мы расскажем в отдельной статье этого номера, поэтому здесь на них останавливаться не будем. Следует лишь отметить, что эти решения хорошо подходят для систем, нагрузка на которые схожа с OLTP.
Вторым большим классом NoSQL-систем являются проекты, обеспечивающие горизонтально масштабируемую платформу для хранения и параллельной обработки данных. Они больше подходят для задач с «тяжелыми» запросами, свойственными DWH (Data Warehouse) или бизнес-аналитике. Наиболее популярным и известным проектом является Apache Hadoop, состав и принципы работы которого мы рассмотрим более подробно.
Маленький «слон» для Больших Данных
Не вдаваясь глубоко в технические подробности, можно сказать, что Hadoop состоит из двух основных компонент: распределенной кластерной системы Hadoop Distributed File System (HDFS) и программного интерфейса Map/Reduce. На основе HDFS и Map/Reduce разработан ряд продуктов (см. рис. 3).
Чтобы оценить достоинства, которыми обладает Hadoop, необходимо хорошо понимать принципы работы его компонент. Рассмотрим архитектуру решения более подробно.
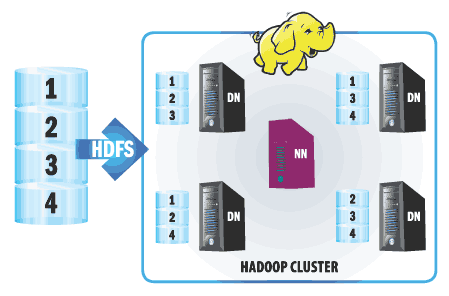
HDFS представляет собой распределенную, линейно-масштабируемую и устойчивую к отказам кластерную файловую систему. Фактически это кластер из множества однотипных узлов хранения данных с внутренними дисками, объединенных общей LAN. Кроме узлов хранения (Data Nodes), в кластере присутствует специальный узел, ответственный за управление и хранение метаинформации о HDFS (Name Node).
Запись в HDFS осуществляется блоками по 64 MБ. Такой большой размер обусловлен тем, что HDFS изначально спроектирована для хранения и обработки весьма значительного объема данных. Запись блоков данных по узлам кластера происходит равномерно, причем каждый блок имеет, как минимум, одну копию данных на другом узле (см. рис. 4).
Рис. 3. Семейство продуктов Hadoop 
Таким образом, HDFS защищена от выхода из строя любого из узлов кластера (за исключением Name Node, который надо резервировать). Количество резервных копий блоков данных можно увеличивать, тем самым добиваясь отказоустойчивости двух или более узлов кластера одновременно. При добавлении нового узла в HDFS-кластер происходит автоматическое перераспределение блоков данных с учетом новой топологии, при этом емкость HDFS также увеличивается автоматически, не требуя каких-либо действий со стороны администратора.
Как следует из вышесказанного, HDFS сама по себе не представляет ничего революционного. Самое интересное начинается при использовании связки HDFS и программного интерфейса Map/Reduce.
При разработке Map/Reduce предполагалось создать технологию, способную за ограниченное время обрабатывать огромные объемы данных. Дело в том, что классическая парадигма сервера(-ов), имеющих совместный доступ к центральному хранилищу данных, перестает работать при их неограниченном объеме, поскольку вертикальное масштабирование серверов, массивов и каналов передачи данных ограничено. Была необходима система, масштабируемая горизонтально и не требующая передачи всех данных счетным узлам. Именно таким образом и спроектирован Map/Reduce.
Основные принципы, заложенные в программный интерфейс Map/Reduce, можно сформулировать следующим образом:
- не данные передаются программе обработки, а программа – данным;
- данные всегда обрабатываются параллельно;
- параллельность обработки заложена архитектурно в программном интерфейсе Map/Reduce и не требует дополнительного кодирования от разработчика.
В этой системе запрос на обработку данных представляет собой небольшую программу. По умолчанию она написана на языке Java, но фактически можно использовать любой язык программирования.
Своим названием программный интерфейс Map/Reduce обязан двум основным задачам, которые всегда выполняются при запуске в нем любого задания. Для того чтобы наглядно представить принципы его работы, рассмотрим задачу тарификации абонентов вымышленного оператора сотовой связи MR Telecom. Предположим, что все данные о разговорах абонентов наш сотовый оператор помещает в директорию /calls, куда также попадают сообщения об ошибках и прочая информация. Для выставления счетов абонентам надо подсчитать общее время исходящих звонков для каждого номера. Таким образом, оператора интересуют записи вида «001 1234567 7654321 00:05:14», где первое поле – внутренний номер, второе – номер звонившего абонента, третье – номер вызываемого абонента и, наконец, четвертое – длительность разговора.
Рис. 5. Принцип работы Map/Reduce 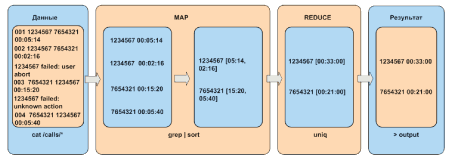
Для решения этой задачи создается небольшая программа, реализующая два метода. Первый – метод Map, который из потока данных на входе выбирает нужные записи и производит агрегацию значений по ключу. В нашем случае ключом служит номер звонившего абонента, а значением – длительность разговора. После работы Map оператор получает ряд ключей с массивом значений для каждого из них (см. рис. 5).
После этого данные обрабатываются методом Reduce. Он выполняет агрегацию значений ключа, в нашем случае просто суммируя время разговоров по каждому номеру. На выходе оператор имеет список абонентов с суммарным временем разговора (см. рис. 5).
Самое интересное, что программный интерфейс Map/Reduce самостоятельно передает и одновременно запускает эту программу на узлах кластера, хранящих обрабатываемые данные. Так как HDFS равномерно распределяет данные по всем узлам, скорее всего, будут задействованы все доступные серверы кластера. Далее результаты работы от всех узлов агрегируются методом Reduce и передаются пользователю.
Таким образом, вместо привычной концепции «база данных и сервер» у нас имеется кластер из множества недорогих узлов, каждый узел которого является и хранилищем, и обработчиком данных, а само понятие «база данных» отсутствует.
Стоит отметить, что подобная система обладает двумя важными характеристиками. Во-первых, любой сколь угодно сложный анализ большого объема данных сводится к их обработке на локальных дисках сервера, поэтому максимально возможное время реакции хорошо прогнозируемо. Во-вторых, система масштабируется симметрично и линейно – при добавлении новых узлов возрастают и вычислительная мощность, и дисковая емкость, поэтому время обработки данных не зависит от их объема.
Табл. 1. Сравнение rDBMS с Hadoop 
Как видно из описания, система на базе Hadoop выглядит очень привлекательно, и идея заменить дорогие серверы с не менее дорогими прикладным обеспечением и системой хранения данных на доступный кластер со свободно распространяемым ПО возникла у многих специалистов. Но, разумеется, все не так радужно, как выглядит на первый взгляд, иначе бы мы наблюдали повсеместное внедрение Hadoop-систем во всех DWH-проектах.
Тест на сообразительность
По сравнению с RDBMS (особенно с параллельными) Hadoop имеет два недостатка. Первый очевиден: интерфейс Map/Reduce не совместим с SQL1, поэтому приложение для работы с Hadoop придется переписывать. Второй проблемой является то, что, несмотря на все возможности параллельной обработки данных, по производительности Hadoop проигрывает существующим решениям на базе параллельных RDBMS. Этот вопрос долгое время был предметом жарких дискуссий между сторонниками и противниками RDBMS, пока группа известных специалистов по базам данных во главе с Майклом Стоунбрейкером и Дэвидом Девиттом не провела ряд испытаний, результаты которых были приведены в статье «A Comparison of Approaches to Large-Scale Data Analysis».
Результаты тестов были довольно неутешительны для сторонников новых технологий. Система Hadoop сравнивалась с параллельными RDBMS Vertica и СУБД-Х, которые по итогам продемонстрировали существенное превосходство в производительности над Hadoop при выполнении ряда тестовых задач анализа данных большого объема. В среднем для всех пяти задач на кластере из 100 узлов СУБД-X оказалась в 3,2 раза быстрее Hadoop, а Vertica – в 2,3 раза быстрее СУБД-X.
По мнению авторов тестов, преимущество в производительности, свойственное обеим системам баз данных, является результатом применения ряда технологий, разработанных в последние 25 лет. Это индексы в виде B-деревьев, ускоряющие выполнение операций выборки, новые механизмы хранения данных (например, поколоночное хранение), эффективные методы сжатия данных с возможностью выполнять операции прямо над ними и сложные параллельные алгоритмы для выполнения запросов над большими объемами реляционных данных.
Табл. 2. Сравнение rDBMS с noSqL-системами 
В случае Hadoop система вынуждена всегда начинать выполнение запроса с просмотра всего входного набора данных, реализуя задачу, схожую с ETL-процессом (Extract, Transform and Load), которая в RDBMS уже выполнена. Но, хотя авторы не были удивлены относительным превосходством в производительности двух параллельных систем баз данных, на них произвела впечатление сравнительная простота установки и использования Hadoop.
После спада шумихи вокруг Hadoop стало ясно, что «серебряной пули» все-таки нет, и новые технологии имеют не только преимущества, но и недостатки. Краткий перечень «за» и «против» использования Hadoop приведен в табл. 1, и ИТ-специалисты должны сами решить, в каком случае применять (или не применять) Hadoop.
Большое будущее
Несмотря на множество проблем, которые могут возникнуть при применении NoSQL-технологий, одно можно сказать совершенно определенно – реляционные СУБД теперь не являются единственным средством работы с данными.
Множество решений, связанных с обработкой больших объемов данных, в ближайшее время будут использовать как реляционные СУБД, так и NoSQL-технологии, которые дополняют возможности друг друга
Это не значит, что СУБД вдруг устарели и будут вытеснены новыми прогрессивными NoSQL-системами. Более того, реляционные СУБД будут оставаться доминирующей технологией в OLTP-системах и во всех небольших и средних DWH-решениях в обозримом будущем. В то же время множество решений, связанных с обработкой больших объемов данных, в ближайшее время будут использовать как реляционные СУБД, так и NoSQL-технологии, которые дополняют возможности друг друга (см. табл. 2).
Со временем более отчетливо будет видна та ниша, где применение NoSQL является наиболее эффективным и органичным. Уже сейчас есть несколько областей, где использование этой технологии имеет вполне радужные перспективы. Специалисты, которые проводили сравнительное тестирование Hadoop с параллельными СУБД, в 2010 году опубликовали статью с красноречивым названием «MapReduce and Parallel DBMSs: Friends or Foes?» («MapReduce и параллельные СУБД: друзья или враги?»), где отметили как минимум пять таких областей.
ETL и наборы данных, читаемые только единожды
Каноническое использование Hadoop характеризуется шаблоном из пяти операций:
- чтение журнальной информации из нескольких разных источников;
- разбор и очистка журнальных данных;
- выполнение сложных преобразований;
- принятие решения о том, какие атрибутивные данные следует сохранить;
- загрузка информации в СУБД или другую СХД.
Эти шаги аналогичны фазам извлечения, преобразования и загрузки в системах ETL. Hadoop, по сути, создает из необработанных данных полезную информацию, которая потребляется другой системой хранения. Поэтому решение можно считать параллельной системой ETL общего назначения. Она является хорошей унифицированной заменой различным подсистемам очистки и загрузки данных, зачастую разрабатываемым компаниями самостоятельно.
Несмотря на проблемы, которые могут возникнуть при применении NoSQL-технологий, ясно одно – реляционные СУБД не являются единственным средством работы с данными
Сложная аналитика. Во многих приложениях интеллектуального анализа (Data Mining) и кластеризации данных программе приходится производить несколько проходов по данным. Для этого требуется сложная программа обработки потоков информации, в которой выходные данные одной части приложения являются входными данными другой его части. Hadoop является хорошим кандидатом для реализации таких приложений.
Работа с частично структурированными данными
В отличие от СУБД, NoSQL-системам не требуется, чтобы пользователи определяли схемы своих данных. Поэтому они легко сохраняют и обрабатывают так называемые частично структурированные данные. В этом ключе потенциальными пользователями NoSQL-технологий являются различные интернет-проекты, специфика которых, как правило, подразумевает работу именно с такой информацией.
Анализ на скорую руку
Одним из недостатков многих современных параллельных СУБД является то, что их трудно должным образом устанавливать и конфигурировать. Пользователи часто сталкиваются с мириадами параметров настройки, которые необходимо корректно установить, чтобы добиться эффективной работы системы. После установки и правильного конфигурирования СУБД программисты должны определить схему своих данных (если она еще не существует), а затем загрузить данные в систему. Этот процесс длится значительно дольше, чем в Hadoop, потому что СУБД должна разобрать и проверить в загружаемых кортежах каждый элемент данных. NoSQL- программисты же по умолчанию (значит, чаще всего) загружают свои данные путем их простого копирования в распределенную блочную систему хранения, на которой основывается система Map/Reduce. Соответственно, если вам нужно выполнить единичный анализ текущих данных, предпочтительнее модель NoSQL со своим небольшим временем раскрутки.
Производственная эксплуатация при ограниченном бюджете
Eще одним достоинством систем NoSQL является то, что почти все они созданы в проектах Open Source и доступны бесплатно. СУБД, в частности параллельные, стоят недешево. И если корпоративные пользователи с высоким уровнем потребностей и большим бюджетом могут позволить себе коммерческую систему и все инструментальные средства, то бизнес с более умеренными бюджетом и уровнем требований зачастую предпочитает системы с открытыми исходными текстами. Поэтому для компаний так называемого среднего уровня вариант аналитической системы на базе NoSQL выглядит достаточно привлекательно.


