 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Слушаем, слышим, анализируем: как работает распознавание речи?
В каких отраслях можно использовать подобные решения?
5 задач — 5 кейсов.
В детстве я очень любил журнал «Юный техник». Особенно запомнился выпуск от 1989 года: статья называлась «Сквош по 5-му каналу». Пожалуй, именно она навсегда приковала мой интерес к электронике — так сказать, триггернуло. Затем было изготовление первого радиоприемника, усилителя и акустики. Иногда пытался «заколдовать» (запрограммировать) калькулятор МК-61 🙂 Ну а с появлением у друга ZX Spectrum я вкусил программирование на бейсике и долгое ожидание загрузки игр с бобинника.
Много кода утекло с тех пор — компьютеры стали меньше и быстрее. Что говорить, Raspberry Pi намного умнее тех же «ДВК» и «БК-001». Увеличение производительности железа и появление графических процессоров привели к активному росту разработок в сфере ИИ. Сейчас, наверное, каждый от мала до велика (исключение — моя мама :)) знает, кто такие Алиса и Siri.
Сегодня я расскажу о применении современных ИИ-технологий для решения бизнес-задач. Речь пойдет о диалоговых системах с обработкой естественного языка. К их компонентам относятся: автоматическое распознавание речи (ASR), обработка естественного языка (NLP) и синтез речи (TTS).
Итак, поехали!
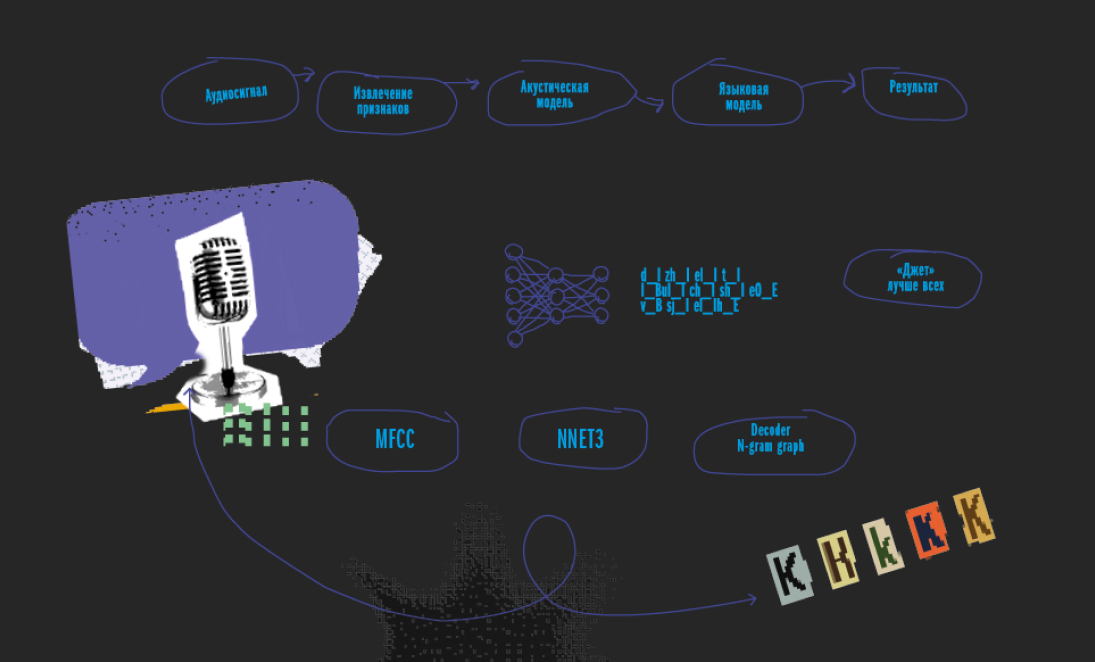
Процесс преобразования речи в текст состоит из трех этапов: извлечения признаков (преобразование аудиосигнала в спектральные характеристики, подходящие для задач машинного обучения), разработки и обучения акустической и языковой моделей. Модели обучаются независимо друг от друга.
Для тренировки акустической модели используют размеченные аудиозаписи на целевом языке, например, аудиокниги. Она предсказывает фонемы (минимальные смыслоразличительные единицы языка) с учетом спектральных звуковых характеристик, полученных с помощью экстрактора признаков. В русском языке, к примеру, 42 фонемы. Сочетания фонем дают слова — используя словарь, мы предсказываем их и строим предложения.
Языковая модель, или модель n-gram, предсказывает следующее слово в последовательности. К примеру, во фразе «Мы ___ всех» выше вероятность того, что пропущено слово «лучше», а не слово «ненавидим» (если, конечно, вы не обучили модель чему-то необычному :)). В итоге две модели объединяются, чтобы сформировать основу для распознавания речи.
В большинстве случаев акустическая модель редко дообучается (она знает уже все фонемы), а вот языковая — постоянно. Например, на производстве используется много специальных терминов. Если модель не будет узнавать новые слова или словосочетания, она просто будет выдавать наиболее вероятные, близкие по звучанию варианты.
Что интересно бизнесу
Наибольший интерес представляет связка из технологий распознавания речи и обработки естественного языка. Приведу несколько примеров, где ее можно использовать.
Колл-центр
- Часть задач по общению с пользователями может взять на себя робот. Например, выступить в роли первой линии техподдержки.
- Информирование и телефонные опросы. Наверное, их уже ненавидят все 🙂
- Контроль качества обслуживания: анализ разговоров, отслеживание отдельных слов и фраз оператора и т. д.
Энергоснабжающее предприятие
Голосовой помощник может принимать показания электросчетчиков или регистрировать заявки на устранение неисправностей.
Производственное предприятие
- Промышленное оборудование нуждается в регулярном осмотре. Сотрудник может совершать обход с мобильным устройством — не записывать, а проговаривать и автоматически заносить в отчет информацию. Это особенно актуально для предприятий, где пользоваться блокнотом сложно — из-за грязи, плохого освещения и т. д.
- Интересный кейс — контроль работы оборудования. По специфическому звуку устройства можно определить неисправность!
- Пропускное бюро может передать часть работы автоматизированному терминалу, распознающему речь сотрудников. Если прикрутить сюда еще и распознавание лиц, систему смело можно использовать для подтверждения личности при выдаче пропусков.
Банк
Банкам в первую очередь будет интересен контроль качества обслуживания — анализ телефонных переговоров с клиентами.
Ритейлер
Контроль качества обслуживания на кассе. Среди возможных решений — мобильный жетон или устройство записи в кассовой зоне. Анализируя разговоры сотрудников и клиентов, система может оценивать качество обслуживания по заданным критериям.
Кейс № 1. Сервис автоматической транскрибации
Кейс № 1. Сервис автоматической транскрибации
Задача
Автоматически расшифровывать и переводить в текст видеоотчеты сотрудников аграрного предприятия.
Решение
Мы разрабатывали для заказчика сервис транскрибации видеоотчетов. Сотрудники компании, работающие в полях, снимают на мобильные устройства видео обо всех проделанных операциях. Например, сколько удобрений нанесли на конкретный участок поля. В конце рабочей смены записи принимают и вручную обрабатывают специалисты по учету материалов.
Наше решение помогает автоматизировать процесс: система выделяет из отчетов аудио и трансформирует в текст. Благодаря этому специалисты могут быстрее извлекать из записей важную информацию. К примеру, название и объем удобрения, которое использовал сотрудник, или дату и время операции.
Детали
История разработки сервиса началась с данных, которые поначалу казались весьма приличными. На первом этапе заказчик хотел проверить, можно ли хоть что-то с ними сделать и получить из этого какой-то результат. Такая постановка задачи показалась мне странной, ведь данные были довольно качественными… Спойлер: радовался я недолго 🙂
Звуковая дорожка тестового видео представляла собой четкий, записанный чуть ли не дикторским голосом отчет тракториста Иванова: «Поле двадцать пять, оператор Иванов Алексей Михайлович, препарат Аксиал 200, 100 литров, трактор МТЗ-80, госномер …». Запись велась на улице на фоне работающего трактора.
Я набросал простой скрипт по выделению аудиодорожки из видео, прогнал ее через «распознавалку» (движок транскрибации речи) и удивился хорошему результату работы модели. Единственной проблемой были специальные термины, которых, само собой, не было в словаре базовой модели. Не беда — вооружившись списком терминов, я собрал новую версию, которая понимала слова вроде «Аксиал». Теперь все работало как положено: я потирал руки, а заказчик на радостях прислал еще аж 30 видеоотчетов.
Вот тут-то нас и ожидал нас сюрприз… В начале мы, как и положено, передали видео на разметку коллегам. Им нужно было прослушать отчеты и написать эталонные тексты. Когда тексты попали ко мне в руки, я прогнал их через распознавалку и удивился: откуда такие серьезные ошибки в точности распознавания? Тогда я решил сам прослушать отчеты — смеялся и плакал одновременно. Речь операторов звучала как тихий фон к ветру, дующему в микрофон. 🙂 Было очень жалко коллег, которые пытались хоть что-то в этом разобрать. Вот вам и приличные данные — где-то половина оказалась совсем низкого качества. Естественно, переходить ко второму этапу — извлечению сущностей — в таких условиях не было смысла. А заказчик в итоге пропал: видимо, понял, что заставить людей наговаривать отчеты по инструкции и в тишине — такая себе задачка.
При работе с данными мы ощутили всю мощь «отлаженного» процесса формирования отчетов. Вот пример распознанного текста: «Вась, впритирку не ставьте. Протер, вон, видишь. Вась, разгладь мешки.» 🙂
Выводы
- Модели нужно проверять. Это избавит от лишней работы.
- Автоматизация невозможна без корректировки бизнес-процессов. Заказчик смог бы реализовать проект, если бы изменил требования к формированию видеоотчетов.
Кейс № 2. Система обзвона и сбора данных
Кейс № 2. Система обзвона и сбора данных
Задача
Автоматизировать обзвон и уточнение статуса нерешенных заявок, которые проводят специалисты первой линии техподдержки.
Решение
Мы разработали для крупной логистической компании электронного помощника. Система просматривает список незакрытых заявок, обзванивает ответственных лиц, уточняет статусы в режиме диалога и сохраняет результаты в отчет.
При разработке помощника мы использовали технологии распознавания и синтеза речи, обработки естественного языка. Интегрировали систему с IP-телефонией.
Детали
Начнем с того, что эту задачу мы решали достаточно давно. С тех пор технологии изменились, и многое я бы сделал по-другому.
Для распознавания речи мы взяли популярный движок от компании ЦРТ. Подружиться с API этого монстра удалось достаточно быстро. В качестве сердца сервиса выбрали решение Asterisk. Это система компьютерной телефонии с открытым исходным кодом. Именно она осуществляет обзвон для уточнения статуса заявок и собирает необходимую информацию.
Следующей задачей было научить обзвонщика говорить. Первым и единственным вариантом был синтез речи, поскольку озвучиваемая информация менялась динамически — нужно было уточнять статусы разных заявок. Мы собрали прототип, и началось самое интересное — тестирование.
В качестве подопытного региона выбрали Тверскую область. В процессе мы поняли, что это был не лучший вариант. Нерешенные заявки в основном относились к очень уж глухим местам, что, конечно, наложило отпечаток на работу обзвонщика. Людей на местах не предупредили, и большинство почему-то подумало, что с ними говорит человек 🙂 Но сделаем скидку на то, что это был 2018 год. Тем не менее, несмотря на все трудности, обзвонщик отработал очень даже неплохо. В ходе пилота электронный помощник показал эффективность свыше 75%.
Выводы
- Персонал на местах может быть не готов к использованию подобных систем. Перед опытной эксплуатацией нужно проводить инструктаж — это избавит от многих проблем.
- Продукт Asterisk хорошо себя показал. Его вполне можно использовать и для решения более серьезных задач.
Кейс № 3. Сервис бронирования переговорных
Кейс № 3. Сервис бронирования переговорных
Задача
Автоматизировать процесс бронирования переговорных комнат.
Решение
Мы разработали прототип электронного помощника для бронирования переговорных. Система помогает выбрать и забронировать комнату в режиме чата: можно написать все в одном предложении или в формате «вопрос–ответ».
Детали
Задача возникла совершенно логичным образом. Есть переговорки — чтобы забронировать комнату, нужно отправить письмо администратору. Это неудобно и несовременно. Просто автоматизировать процесс и сделать интерфейс для администратора — не наш выбор. Мы пошли другим путем и решили практически полностью передать задачу системе.
Архитектура решения выглядит так: во главе системы стоит чат — мы использовали Telegram-бота. Далее сердце — диалоговая система с функционалом извлечения именованных сущностей из пользовательского текста. Например, номер переговорной, дата, список участников и др.
Кейс № 4. Сервис для анализа аудио- и видеоданных
Кейс № 4. Сервис для анализа аудио- и видеоданных
Задача
Автоматизировать процесс ручного анализа аудио- и заменить ручной анализ видеоматериалов (аудио) на автоматический.
Решение
В компании по анализу, которая занимается анализом и формированием рейтинга фильмов, работает более 10 операторов. Каждый из них может обработать не более одного фильма в день. Чтобы увеличить КПД, можно использовать систему, которая будет транскрибировать выделенные аудио- и видеоматериалы и искать в них запрещенный контент.
Детали
Решение оптимизировано для многопоточной обработки аудио на графических адаптерах и извлечения именованных сущностей (словари запрещенного контента). Автономная система может обработать более 500 фильмов в сутки.
Кейс № 5. Колонка «Мира» 🙂
Кейс № 5. Колонка «Мира» 🙂
Задача
Разработать автономного голосового помощника для палаты медицинского учреждения.
Решение
ПАК на базе мобильного ARM-процессора для распознавания, синтеза речи и управления умными устройствами. Полноценной промышленной системы не получилось, но прототип разработали 🙂

Детали
Давным-давно, в одной не очень далекой галактике… Стоп, я же пишу о другом!
Как-то нам прилетела интересная задачка. Заказчик из одного крупного медицинского центра попросил сделать небольшую коробочку с голосовым помощником на борту. Только вот помощник (в отличие от той же «Алисы») должен был работать автономно — без интернета.
Как и положено, у заказчика не было ТЗ, что отправило нашу фантазию в полет. Проект начался с архитектуры, состава демокомплекта и дизайна. Сложность с архитектурой была в том, что устройство должно было быть компактным, но при этом производительным. А алгоритмы операций над матрицами (основа всех моделей) очень уж прожорливы и любят массивные железки.
Мы выбрали плату известного китайского производителя Orange Pi — аж с 6-ядерным процессором. Микрофон, блок питания и прочая мелочевка нашлись без проблем. Первый сюрприз выдал процессор: оказалось, он греется сильнее, чем заявлено в документации. Решение подбирали долго — в итоге одной из стенок устройства стал огромный радиатор (который, к слову, неплохо вписался в общий дизайн). Еще мы реализовали на передней панели что-то вроде светомузыки... Шучу 🙂 Под покровом прозрачного оргстекла скрывались цветные светодиоды. Они подмигивали или упорно светились в такт работы коробки.
Отдельно хочется рассказать историю появления имени голосового помощника. У нас был целый конкурс, ведь оно должно было быть кратким, уникальным, да и еще легко произносимым. Какие только варианты не предлагали коллеги — и Айка, и Кира. Но в итоге первенца назвали «Мира».
Теперь о функционале. «Мира» понимала речь и отвечала. Мы научили ее нескольким командам («Включи свет», «Включи чайник», «Включи музыку» и т. д.), кроме того, с ней можно было просто поболтать. Также коробка позволяла управлять умными устройствами — для демо мы даже сделали кастомную прошивку для розеток Digma. И еще одна важная функция — «Мира» понимала мат (но не говорила на нем) и предупреждала матерящихся, что так делать плохо 🙂
Продолжим: программное обеспечение — ох уж эти баги… Первой и, как оказалось, самой сложной задачей было найти стабильную прошивку для мобильного процессора. Такую, чтобы ядро Linux поддерживало все периферийные устройства. Многое было перепробовано, «родная» не встала, а вот от Armbian подошла. Остальная программная начинка зашла без проблем. Разве что пришлось повозиться с адаптацией языковой и акустической моделей для С и собрать модули с поддержкой некоторых функций процессора — опять же, для ускорения вычислений.
В итоге во главе решения встал Python, к которому мы прилепили модули распознавания речи, захвата и воспроизведения звука, а также модуль работы с портами ввода-вывода. По итогу «Мира» кричала, слушала и мигала 🙂 И музыку приятно было включать: акустическое оформление мы все же сделали и динамик подобрали качественный.
Теперь расскажу о тестировании нашего детища. Мы написали инструкцию — как пользоваться и что говорить — и с добрым словом отправили «Миру» заказчику. Продолжения проект не получил, но во время пилота мы успели сделать целых два экземпляра прекрасной и послушной «Миры» 🙂 Какие выводы можно сделать из всего этого?
- Она говорит!
- Оказывается, влазит 🙂
- Вся сила в команде.
- Возможно все.
А теперь серьезные выводы
- Даже если проект не взлетел, это была работа не «в мусор», а в RnD.
- Качественное распознавание речи вполне может работать на автономных мобильных процессорах.
- Сложные ПАКи нам под силу. Экспертиза позволяет закрыть весь пул технических потребностей: 3D-дизайн, схемотехнику, разработку на С и под ARM, теорию акустики (да, и такое было). Даже работу с паяльником, в конце концов 🙂

Александр Воронцов
Руководитель направления по продвижению омниканальных решений компании «Инфосистемы Джет»
Экспертный комментарий
Речевая аналитика — не бот-платформа, с которой ее часто путают. Ее основная задача — не автоматизация рутинных обращений, а предоставление знаний для принятия решений.
Упрощенно система состоит из двух компонентов: движка распознавания звонков (Auto Speech Recognition, или ASR) и интерфейса для работы супервизора/аналитика.
Базовый интерфейс имеет несколько экранов:
1. Поиск распознанных звонков:
- по фильтрам — фразам, эмоциональной окраске разговора и параметрам (длительность, оператор, воронка продаж, клиент и т. д.);
- по предызготовленным и созданным пользователями категориям (фильтрам) звонков по параметрам.
2. Изучение конкретного звонка — голосовая дорожка, распознанный текст, параметры звонка, автооценка системой и т. д.
3. Инструментарий создания:
- словарей — набора слов, которые объединены одной темой, например, словарь «Повторные звонки» содержит выражения/слова «звоню второй раз», «не хочу перезванивать» и т. д.;
- категория (фильтр) — набор правил (что должен/не должен говорить оператор/клиент) и словарей, позволяющий быстро работать с регулярно изучаемыми категориями звонков.
4. Аналитика — отчеты и дэшборды с основными показателями, извлекаемыми на основе категорий (% звонков, объемы, минуты, доли, эмоциональная окраска разговоров, токсичность и т. д.).
Какие кейсы можно решать с помощью этого инструментария?
1. Классические кейсы контакт-центра:
- Если среднее время обработки звонка (AHT) высокое, можно поработать над его снижением. При стоимости одной минуты разговора оператора в ~15 рублей снижение AHT с 5,5 до 5 минут на объеме 3 600 000 минут в год (контакт-центр на 60–80 операторов) может обеспечить экономию порядка 15–20 млн рублей.
- Показатель повторных контактов (звонков и чатов) в КЦ зачастую не отслеживается. При этом он может составлять 10–20% в зависимости от типа бизнеса. При внедрении речевой аналитики этот показатель реально сократить в 2–3 раза, что также значительно скажется на снижении объема минут.
На деле классических кейсов около 20–30 (отслеживание мата и слов-паразитов, оценка качества консультаций, констатация, что проблема клиента не решена и т. д.). Комбинируя механики, можно добиться того, что контакт-центр на 80 человек, который работал «запыхавшись» и не мог соблюсти Service Level в 80%, достигнет и перебьет этот показатель, обслуживая большее число обращений, чем раньше.
2. Кейсы продаж:
- Отток клиентов в B2B/B2C — клиенты часто изъявляют желание уйти до момента реального ухода. Чем позднее бизнес реагирует, тем сложнее и дороже удержать клиента. Речевая аналитика мониторит сигналы оттока (фразы, угрозы) и через интеграцию с CRM передает в калькулируемое поле «вероятность оттока». При превышении допустимой величины этого показателя менеджер начинает работать с конкретным клиентом для упреждения ухода. В зависимости от типа и профиля бизнеса механика будет отличаться. Реальные показатели, которых можно достичь: снижение стоимости удержания клиента на 15–40%, снижение оттока на 5–20%.
- Конверсия продаж. В крупных отделах продаж очень важно понимать, как работают те или иные скрипты, механики, менеджеры. Речевая аналитика позволяет сортировать звонки по успешным/не успешным сделкам и улучшать механики/акции в зависимости от результативности.
Подведем итог. Речевая аналитика — не только инструмент классической оптимизации контакт-центра (научить вежливости, результативности и т. д.), но и продукт для других областей, например, для повышения продаж и сохранения клиентов через абсолютную прозрачность голосовых коммуникаций с ними.


