 Подписаться
Подписаться Читать в телеграм
Читать в телеграм

Угрозы для российского бизнеса. Откуда ждать проблем?
Чек-лист «Что делать, чтобы работа компании внезапно не остановилась».
Наши кейсы.
Сначала мы пройдемся по угрозам, которые сейчас волнуют российский бизнес.
Исход вендоров
В новой реальности есть вероятность, что какое-то критичное СЗИ лишится своих ключевых свойств или вообще превратится в «кирпич». При этом если on-premise решение еще какое-то время будет продолжать работать, то с облачными продуктами далеко не все так однозначно. Крупнейшие иностранные поставщики облачных решений, например, Amazon Web Services, Microsoft Azure, либо приостановили регистрацию новых клиентов из России, либо вовсе прекратили продажи. Разумеется, никто не закрывается в один день, однако стоит ожидать, что они могут ввести и более масштабные санкции против российских компаний. Бизнесу нужно быстро решить для себя: переносить инфраструктуру в on-premise или мигрировать в другие, в том числе отечественные, облака. Пандемия изменила нагрузку на инфраструктуру ИТ-компаний, так что облака сейчас не могут не развиваться.
Еще один риск — перестанут работать VPN-клиенты. Если альтернативные варианты доступа к ним не были продуманы, в один момент сотрудники потеряют доступ к корпоративным ресурсам.
Кибератаки
Параллельно с уходом вендоров российский бизнес переживает рекордную по своим масштабам волну кибератак. Количество атак на e-comm и сферу развлечений по сравнению с прошлой весной выросло в 2,5 раза. Также увеличилось число атак, реализованных с помощью вирусов-шифровальщиков, — оно составило около 41 тысячи инцидентов.
Очевидно, рост киберугроз напрямую влияет на обеспечение непрерывности бизнеса. Злоумышленники могут просто положить сервисы, например, как в случае с Rutube. Также был зафиксирован серьезный сбой в работе Wildberries. DDoS-атакам подверглись сайты авиакомпаний «Россия», «Аврора», АЛРОСА, «Ямал», NordStar и Smartavia — их сервисы долго были недоступны. Все это подтверждает: бизнес может остановиться в любой момент, и в зоне риска находятся все отечественные компании.
Человеческий фактор
С усложнением бизнес-процессов, развитием технологий существенно возрастает роль человека, поэтому не стоит забывать и о старых проблемах, существующих вне зависимости от кризисов. Это человеческий фактор и бытовые происшествия: затопления, пожары, перебои с электричеством. Компания может подготовиться к кибератаке, но если ИТ-подразделение перегружено работой, ошибки в конфигурировании, например, оборудования ЦОД, неизбежны. ИТ-специалисты могут добавить неверную информацию в файлы конфигурации или в запарке проигнорировать рекомендации, которые дали поставщики при установке оборудования. Это может привести к частичной недоступности сети, простоям оборудования.
План действий
Есть множество шагов, обеспечивающих управление непрерывностью бизнеса (УНБ): актуализация релевантной матрицы рисков, проведение анализа воздействия на бизнес, регулярные тестирования, определение максимально возможного объема безвозвратно потерянных данных (RPO) и мощностей, которые необходимы для СРК, и др.
При этом сегодня как никогда важна скорость реагирования, нужно выполнение минимальных и простейших шагов, чтобы уменьшить последствия сбоев. Первичная документация с регламентами реагирования на киберинциденты должна быть написана простым и понятным языком: «если нет света — звони туда», «если пожар — действуй так и беги туда». Главная проблема в случае ЧП — ступор и незнание, к кому обратиться за указаниями и разъяснениями. После подготовки верхнеуровневых планов можно задумываться над тем, чтобы углублять вопрос непрерывности.
Мы составили чек-лист, что необходимо сделать для обеспечения непрерывности бизнеса.
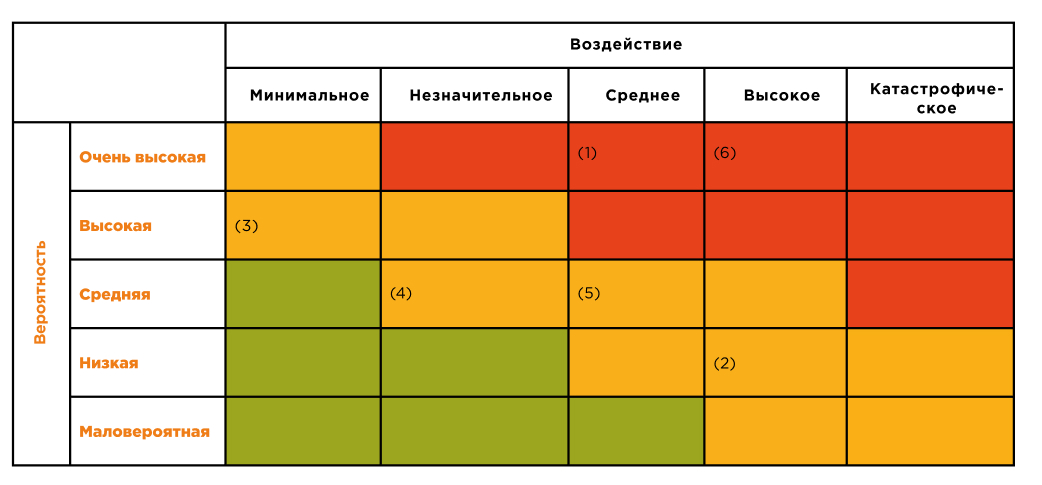
1. Определите релевантные для вашей компании риски нарушения непрерывности и согласуйте их с руководством. Не нужно использовать суперсложную методику определения рисков и угроз. Например, можно воспользоваться методом Дельфи.
Возьмем следующие риски (см. табл. 1):
- DDoS-атака (1)
- Пожар в офисе (2)
- Перебои с электричеством (3)
- Аварии в инфраструктуре ЦОД (4)
- Обрыв телекоммуникационных каналов связи (5)
- Угроза отключения от SWIFT (6)
НА ЗАМЕТКУ
Метод Дельфи позволяет учесть мнение группы людей, имеющих отношение к тому или иному вопросу или ситуации. Сначала с ними проводятся мозговые штурмы, опросы и интервью. Затем позиции экспертов анализируются и последовательно объединяются. Обобщение мнений позволяет выработать оптимальное решение.
2. Определите ключевые системы и процессы для вашей компании. Достаточно небольшой анкеты для общения с бизнесом (см. рис. 1 и табл. 2). В ней будет указана информация о системе: кто за нее отвечает, время, за которое нужно восстановиться, а также максимально допустимый период времени, за который вы готовы лишиться данных из нее.


3. Проверьте параметры резервного копирования ключевых систем: все ли утвержденные бизнесом RPO выдерживаются? Систему могли создать много лет назад, и никто не помнит, как происходит копирование. Узнайте у технических владельцев критичных систем, за счет чего обеспечивается их работоспособность: какое обслуживание им необходимо, какие комплектующие, как скоро закончатся лицензии.
4. Проверьте безопасность СРК. Как правило, современные СРК уже имеют встроенные механизмы защиты от шифровальщиков: Honeypot, защиту базы данных дедупликации. Проверьте, что эти настройки активированы, система выделена в отдельный сегмент и реализованы базовые меры по ее защите.
5. Определите круг людей, которые будут принимать решение в случае критичных нештатных ситуаций, например, экстренно «потушить» все серверы. Иногда драгоценное время уходит, поскольку нет понимания, кто должен дать «целевое указание» на такие действия.
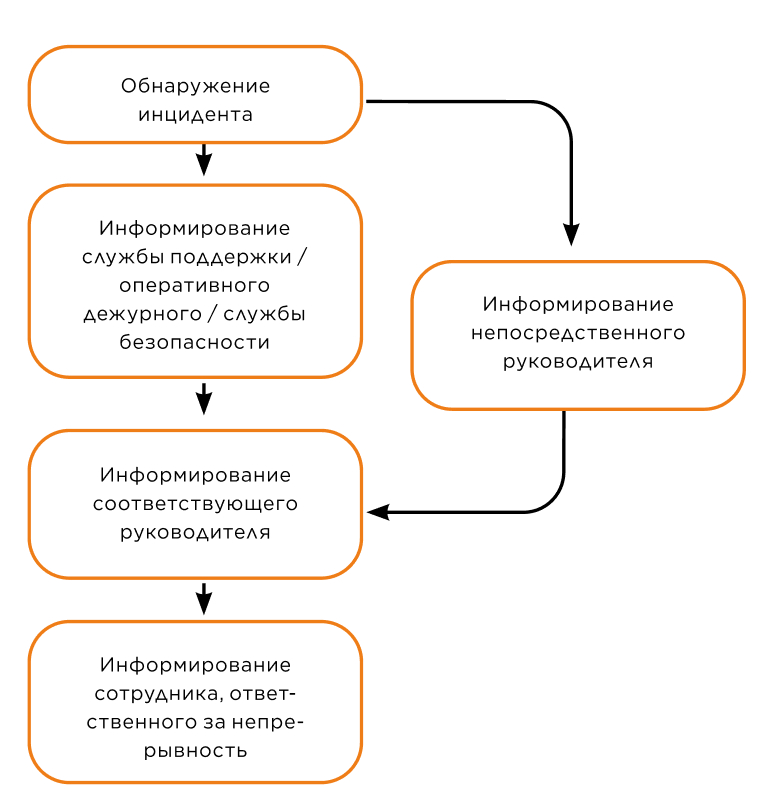
6. Разработайте план коммуникации для ИТ и СБ. Он должен быть максимально простым (см. рис. 2).
7. Создайте альтернативный канал связи на экстренный случай. Например, группу в безопасном мессенджере (Telegram/Signal), куда будут добавлены все ответственные сотрудники, ключевые руководители.
8. Сделайте памятки для пользователей. Памятка может содержать текст «В случае ЧП звонить по этому номеру». И ниже будут указаны номера СБ, ИТ или АХО.
9. Сделайте памятки для ИТ-администраторов для снижения ключевых рисков. Укажите в них, с кем можно связаться на случай поломки ИТ-оборудования, если что-то произошло с каналом связи и т. д.
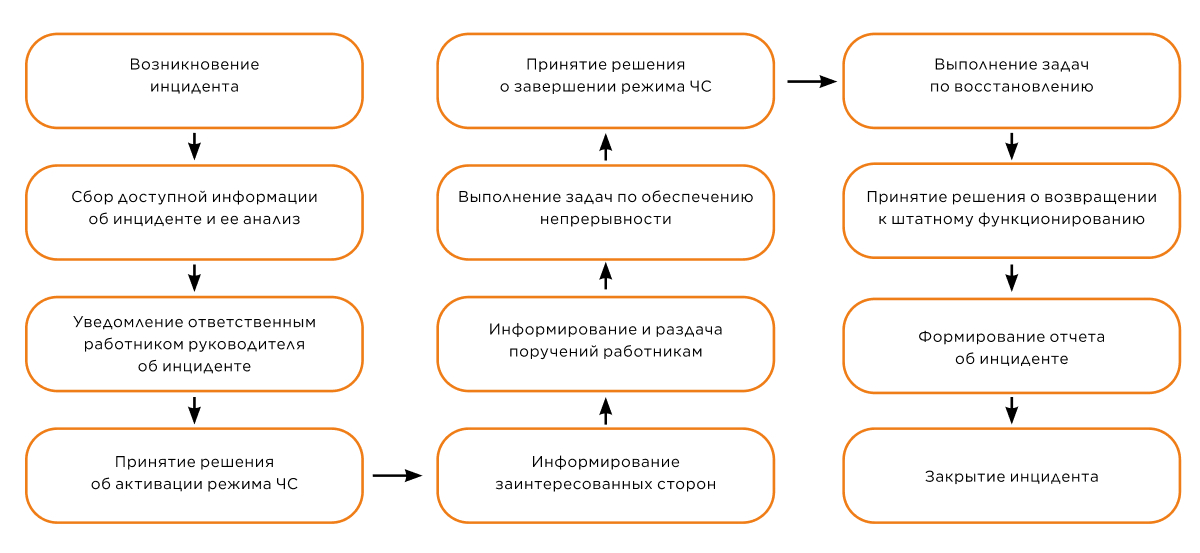
10. Проверьте хотя бы на бумаге подготовленный план реагирования. Его можно оформить в виде блок-схемы для наглядности (см. рис. 3).
Реализовав эти несложные шаги, вы перейдете к более зрелому процессу обеспечения непрерывности в вашей компании.
Ниже мы рассматриваем кейсы из нашего опыта, реализованные за последний год.
Кейс № 1. Медиахолдинг
Наша команда выстроила процесс непрерывности для крупного медиахолдинга. Клиент хотел определить актуальные ключевые риски, выстроить коммуникацию между своим комитетом УНБ, кризисной группой и командой восстановления, проверить, как функционирует система УНБ и т. д. Компания предоставляет пользователям доступ к видеоконтенту 24*7, так что обеспечение бесперебойной работы является важнейшим аспектом ее бизнеса.
Модернизация системы УНБ повысила зрелость процессов непрерывности и восстановления деятельности в компании.
Мы в том числе определили уровень готовности персонала, ИТ-оборудования и других активов.
Проект занял около трех месяцев и включал три блока. Сначала наша команда актуализировала перечень релевантных для компании рисков. Мы разработали методику оценки рисков с учетом специфики заказчика. Определили ключевые риски и согласовали их с компанией, провели их оценку и ранжирование — проанализировали воздействие на бизнес. Для этого наши эксперты проинтервьюировали ключевых сотрудников. В результате заказчик получил список критичных бизнес-процессов, ранжированный по важности восстановления и целевым значениям параметров непрерывности, матрицу зависимостей бизнес-процессов от ИС и качественную оценку ущерба при недоступности бизнес-процессов и информационных систем.
Вторым блоком проекта стала разработка методологических документов — Политики и Плана непрерывности. При разработке Политики мы определили ее цели и принципы, процедуры мониторинга и отчетности в области непрерывности бизнеса, а также этапы жизненного цикла УНБ, основываясь на стандарте ISO 22301:2019. План обеспечения непрерывности включает ролевую модель, критерии, необходимые для классификации чрезвычайных ситуаций, критерии введения режима ЧС, шаблоны сообщений для сотрудников и третьих сторон о введении и прекращении режима ЧС.
В завершение мы протестировали План непрерывности и параллельно обучили фокусную группу сотрудников. А после обучения компания под надзором наших экспертов провела собственное тестирование по одному из рисковых сценариев.
Кейс № 2. Стриминговый сервис
К нам обратился известный потоковый медиасервис за помощью в разработке жизненного цикла УНБ. Заказчику нужно было понять, какие бизнес-процессы можно считать критическими и какие уровни потерь будут для него катастрофическими.
Мы проанализировали потенциальное воздействие рисков на бизнес, выделили критичные для заказчика бизнес-процессы и пороги ущерба. Также выдали рекомендации по дальнейшим шагам для развития системы УНБ — оценке рисков, разработке документации, проведению тестирований и обучению сотрудников.
Проект длился три месяца и включал два этапа. На первом мы разработали методику анализа воздействия рисков на бизнес, а также сопутствующие документы.
На втором этапе мы определили целевые параметры непрерывности бизнес-процессов. Провели интервью с сотрудниками, чтобы понять, как работают бизнес-процессы, и с ИТ-шниками для выявления зависимости бизнес-процессов от ИС. Также определили ресурсы, необходимые для их функционирования, и сроки наступления критичного ущерба от остановки этих процессов.
Наша команда подготовила список критичных бизнес-процессов с целевыми значениями параметров непрерывности, матрицу зависимостей бизнес-процессов от ИС, а также сформировала показатели ущерба по нескольким релевантным критериям потерь.
Отметим, что практически все описанные в чек-листе и кейсах шаги — организационные. Чтобы обеспечить минимальный уровень непрерывности бизнеса, не нужно тратить большие деньги. Но нужно потратить время, чтобы разработать модель угроз, определить параметры прямых и косвенных потерь, понять уровень финансовых и репутационных рисков. Например, сейчас, в моменте, компания должна закрыть самые базовые вопросы. Затем уже можно углублять всю эту историю, внедрять многоуровневые планы и инструкции (например, план эскалации, эвакуации, коммуникации).
***
На наш взгляд, сейчас именно то время, когда нужно просчитать сценарии развития событий и подготовиться к худшему: если уйдут вообще все вендоры, количество кибератак продолжит расти, а обслуживание всей ИТ-инфраструктуры ляжет на плечи компаний.
В то же время в сегодняшнем кризисе можно увидеть немало возможностей: есть пути для развития решений, открываются новые рынки сбыта, можно расширить свой портфель новыми услугами. Предугадать все грядущие кризисы и варианты развития событий невозможно, но можно сделать свой бизнес устойчивее и подготовиться к сложностям.


