 Подписаться
Подписаться Читать в телеграм
Читать в телеграм

В развитых странах рынок технологий и услуг, обеспечивающих непрерывность бизнеса, динамично развивается. Его рост составляет около 25% в год и обусловлен, главным образом, тем, что средние компании вслед за лидерами индустрии активно внедряют у себя технологии управления кризисными ситуациями. При этом все более актуальным становится обеспечение защиты от не катастрофических, но более вероятных чрезвычайных ситуаций.
Средней компании нет смысла защищаться от катастрофы («Godzilla scenario»), если она не сможет выжить от менее масштабных, но более вероятных угроз («from being nibbled to death by rats»).
Индустрия обеспечения непрерывности бизнеса в России находится в зачаточном состоянии. Лидерами по внедрению технологий обеспечения непрерывности ИТ-сервисов в нашей стране являются телекоммуникационные компании и банковский сектор. По мнению авторов, это обусловлено особенностями бизнеса, в котором недопустимы простои в предоставлении услуг, международными требованиями и присутствием иностранного менеджмента в данных секторах рынка.
Российский менталитет по-прежнему характеризуется известной поговоркой: «Пока гром не грянет, мужик не перекрестится», хотя в непрерывности бизнеса следует руководствоваться принципом: «Ной построил ковчег до Великого потопа».
Стратегии обеспечения непрерывности ИТ-сервисов
Не делать ничего
Стратегия состоит в том, что не предпринимаются никакие специальные меры, направленные на снижение рисков от вероятных кризисных ситуаций. Надежда возлагается на то, что в случае ЧС у компании будет достаточно времени и ресурсов для выполнения необходимых шагов по восстановлению работоспособности поврежденного оборудования.
Такой подход оправдан, если операционная деятельность компании позволяет безболезненно для бизнеса прерывать функционирование ИТ-сервисов на время, необходимое для закупки оборудования и выполнения восстановительных работ.
«Построить крепость (fortress)»
Данный вариант снижает вероятность реализации внешних угроз до приемлемого уровня, когда их можно уже не опасаться. Примером решений такого рода могут служить сейфы и саркофаги, надежно защищающие оборудование от внешних воздействий, физическая защита по периметру здания, видео-мониторинг помещений и т.д.
Крепость хорошо защищает только то, что находится внутри нее. ИТ-сервисы, несмотря ни на что, могут остаться уязвимыми, например, за счет потери внешних данных или отсутствия доступа к сайту. На практике в большинстве случаев здания с расположенными в них вычислительными центрами (ВЦ) открыты для доступа множества людей и, следовательно, мало пригодны для «построения крепости».
Резервирование ИТ-сервисов на резервной площадке (continuous processing)
Стратегия этого подхода заключается в создании резервной площадки, развертывании на альтернативной площадке резервных систем и коммуникационных каналов, полностью идентичных продуктивной среде. При этом переключение на альтернативную площадку предоставляемых информационной системой сервисов происходит только в случае чрезвычайной ситуации.
Это решение, как правило, сочетается с организацией альтернативной «теплой» или «горячей» площадки.
«Холодная» площадка
«Холодная» альтернативная площадка – место для размещения нового оборудования, где оно может быть развернуто «с нуля».
«Теплая площадка»
«Теплая» альтернативная площадка – серверное помещение для размещения нового оборудования с проинсталлированным окружением (опорной инфраструктурой), которые позволяют перезапустить сервисы на альтернативной площадке, не доводя до драматического влияния на бизнес вынужденного перерыва в функционировании сервисов.
Такая площадка может иметь большую часть требуемого оборудования за исключением позиций, которые при необходимости быстро доставляются со склада.
«Горячая площадка»
«Горячая» альтернативная площадка обеспечивает эффективное дублирование сервисов с производительностью, достаточной для обслуживания бизнеса. На ней имеется все необходимое для этого оборудование, и в случае чрезвычайной ситуации могут потребоваться лишь работы по инсталляции приложений и данных.
Возможность организации перевести бизнес на альтернативную рабочую площадку значительно повышает ее жизнеспособность. Коммерческие поставщики DR-сервисов обычно ограничивают время предоставления сервисов «горячей» и «теплой» резервных площадок (как правило, шестью неделями). По истечении этого срока, в случае серьезного ЧС, прежде чем вернуться на основную площадку, организации может потребоваться временный перевод бизнеса на «холодную».
Стоимость такого решения наиболее высокая. Она обусловлена в основном стоимостью высокопроизводительных резервных систем, в штатной ситуации нахождящихся в режиме ожидания (наступления ЧС) и, следовательно, в операционной работе не участвующих.
Распределенная обработка (distributed processing)
Стратегия распределенной обработки характеризуется локализацией различных сервисов на нескольких альтернативных площадках. Благодаря этому очень мала вероятность выхода из строя одновременно всех систем даже при катастрофе (не все яйца кладутся в одну корзину). Более того, отдельные сервисы можно задублировать на двух площадках, обеспечивая дополнительную гарантию жизнеспособности информационной системы.
Распределенная обработка организуется таким образом, чтобы иметь возможность восстановить работу приложений на альтернативной площадке. Процесс восстановления значительно облегчается при стандартизации оборудования.
Аутсорсинг ВСР: управление и поддержка
Введение планов обеспечения непрерывности бизнеса (ВСР) может либо осуществляться самой организацией, либо используется аутсорсинг необходимых для этого ресурсов. Однако развитие, сопровождение и тестирование этих планов в любом случае потребуют активного участия специалистов заказчика, как минимум, для того, чтобы предоставить исполнителю требования к системам и детальную информацию о конфигурации оборудования.
Несмотря на то, что в штате компании может не быть аварийных команд, заказчик остается хозяином разработанного процесса. Его усилия по регулярному обучению аварийных групп восстановления и периодическому проведению учебных переключений на резервное оборудование решающим образом определяют эффективность плана аварийного восстановления при наступлении ЧС.
Заказчик, кроме того, осуществляет постоянный контроль и проецирование изменений, происходящих в информационной системе, на ВСР.
Страхование финансовых рисков прерывания ИТ-сервисов
Страхование рисков само по себе, частично компенсируя финансовые потери, никак не гарантирует для попавшей в беду компании сохранность бизнеса. С другой стороны, планом аварийного восстановления должны учитываться процедуры, связанные с оперативным получением страховых выплат при наступлении чрезвычайной сиитуации (для спасения имущества и закупки нового оборудования).
Страхование от потерь прибыли и непредвиденных расходов на восстановление после ЧС осуществляется на ограниченный период времени (обычно 6–12 месяцев). После этого компания предоставлена самой себе, и хотя страхование рисков выглядит привлекательным решением, в очень многих случаях застраховавшие свои риски компании не смогли возобновить свой бизнес. Как бы то ни было, разумное страхование активов, стоимости восстановительных работ и потери прибыли в случае ЧС должно рассматриваться как часть стратегии обеспечения непрерывности бизнеса.
Создание запаса резервного оборудования на складе поставщика (Procurement)
Данная стратегия заключается в том, что в договорах с ключевыми поставщиками оборудования определяются условия формирования на складе запаса критичного для бизнеса оборудования, которое должно быть поставлено заказчику в гарантированные сжатые сроки.
Хранение запасного оборудования на складе эффективно, когда оно относительно дешево, а время его поставки велико. Дополнительные затраты, связанные с созданием и хранением запаса оборудования, должны соизмеряться с потенциальными потерями от простоя, связанного с ожиданием поставки вышедшего из строя оборудования в случае ЧС.
Целесообразно такой подход сочетать с организацией альтернативной «холодной» площадки.
«Budge Up»
Стратегия включает в себя различные способы оптимизации использования существующих производственных площадей и оборудования, например, за счет высвобождения таковых в условиях ЧС от низкоприоритетных сервисов в пользу критически важных.
«Off-site Storage» (удаленное хранилище)
Это удаленное хранилище документов, оборудования, а также данных на дисковых и ленточных накопителях.
Удаленное хранилище данных должно обеспечивать защищенное хранение актуальных данных, получаемых в результате выполнения процедур резервного копирования и архивирования, доступных для восстановления 24 часа в сутки и 365 дней в году.
«Reciprocal Arrangements» — соглашения о сервисном обслуживании на случай ЧС Соглашения о сервисном обслуживании на случай чрезвычайной ситуации плохо работают на практике. Как правило, они не документированы надлежащим образом и не подкреплены SLA (договором об уровне услуг). Такое положение дел приводит к возникновению спорных ситуаций и невыполнению договоренностей, на которые рассчитывал заказчик.

Ключевые параметры обеспечения непрерывности ИТ-сервисов
Ключевыми характеристиками, определяющими требования к непрерывности IT-сервисов, являются параметры (Рис.1):
RPO (целевая точка восстановления) – согласованный с бизнесом интервал времени, предшествующий аварии, за который допускается потеря данных. Иными словами, этот параметр показывает, насколько состояние системы и данных может откатиться назад при ЧС.

RTO (целевое время восстановления) – согласованный с бизнесом интервал времени после аварии, необходимый для восстановления IT-сервисов.
RPO и RTO – краеугольные камни, лежащие в основе выбора технологий защиты данных и защиты систем (на уровне приложений).
Основными технологиями, обеспечивающими защиту данных в ЧС, являются:
- резервное копирование и архивирование данных на удаленной площадке (Crossite backup) с размещением их на ленточных накопителях;
- различные способы репликации данных на удаленную площадку с размещением их на дисковых массивах.
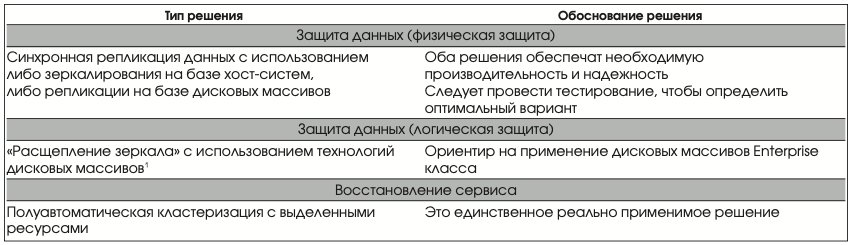
Техническим решением обеспечения защиты систем на уровне приложений являются различные методы удаленного резервирования серверов, в частности, варианты кластерных комплексов, у которых узлы тем или иным способом разносятся на удаленные площадки. Переключение приложения с одного узла на другой происходит автоматически либо вручную. Некоторые простои, связанные с недоступностью приложений, имеют место и в кластерных конфигурациях, но они несоизмеримо ниже, чем в случае одиночных систем. Для кластеров типичный коэффициент готовности Кг = 99,98 (около 1 часа в год).
Избыточность вычислительных ресурсов, за счет которой достигается высокая доступность, подразумевает усложнение вычислительного комплекса и требует дополнительных усилий по управлению. Это увеличивает стоимость решения.
Важной задачей проектной деятельности по обеспечению непрерывности ИТ сервисов в условиях чрезвычайной ситуации является определение требуемого уровня защищенности систем, исходя из необходимых затрат и потенциальной выгоды от уменьшения времени простоя критичных приложений.
Технологические решения по защите систем и данных в ЧС должны сопровождаться разработкой и внедрением организационных мер и процедур, обеспечивающих быстрое и предсказуемое восстановление ИТ сервисов на резервной площадке.
Технологии защиты данных
Приводим варианты типовых технологических решений, расчитанных как на физическое, так и на логическое искажение данных. На практике они должны использоваться в сочетании, чтобы защитить организацию от обоих типов угроз.

Варианты с RPO
~ 0 часов (физическая потеря данных)
Синхронная репликация данных с использованием зеркальных копий томов
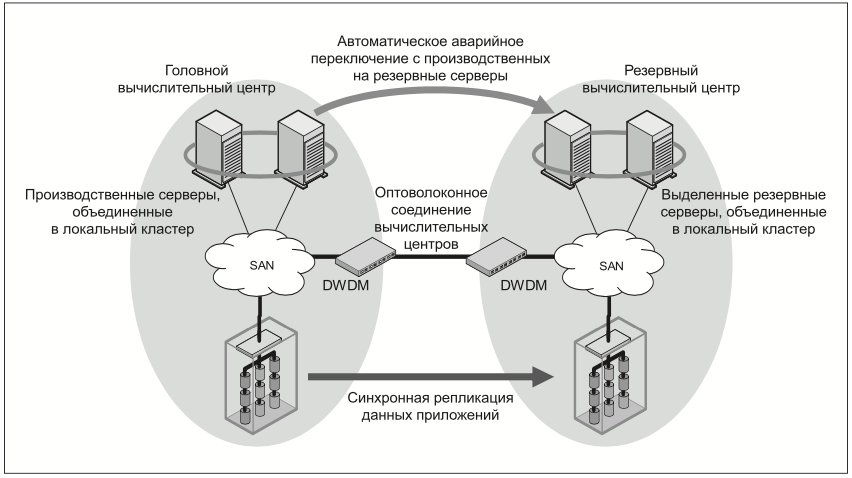
Суть этой технологии состоит в том, что программное обеспечение (ПО) управления томами головного сервера синхронно копирует данные логических томов головного дискового массива на заранее выделенные зеркальные тома удаленного дискового массива (Рис. 2). При этом для связи между вычислительными центрами, как правило, используется высокоскоростная сеть на основе волоконно-оптических каналов связи.
Для управления томами можно использовать стандартное программное обеспечение, встроенное в операционную систему, либо возложить выполнение этой задачи на специализированное ПО, характеризующееся рядом преимуществ, поставленное третьими фирмами.
Качество ПО менеджера томов во многом определяется тем, насколько успешно выполняется инкрементная ресинхронизация двух половин зеркалированного тома в случае временного сбоя связи между дисковыми массивами. Важно максимально быстро повторно синхронизировать зеркала после восстановления связи, чтобы свести к минимуму деградацию производительности сервера и восстановить непротиворечивость данных.
Основные преимущества
- Технология позволяет использовать дисковые массивы разного типа. Это значительно расширяет выбор и позволяет снизить начальные затраты на реализацию системы аварийного восстановления данных.
- При сбое основного дискового массива не требуется выполнение аварийных процедур, связанных с переключением, — процессы ввода-вывода можно продолжать на удаленном массиве. Это значительно облегчает регламент планового технического обслуживания дисковых массивов.
- Технология поддерживается как UNIX-, так и Windows-системами.
Основные недостатки
- Немного пострадает производительность серверов, поскольку управление зеркальным копированием томов требует дополнительной обработки данных (как правило, менеджеры томов отнимают не более 5% ресурсов центрального процессора (ЦП) и памяти сервера).
- Недостаточная пропускная способность сети может негативно повлиять на производительность приложений, особенно тех, которые требуют большого объема ввода-вывода.
- Во время повторной синхронизации после расщепления зеркала непротиворечивость данных нельзя гарантировать до полного завершения синхронизации.

Синхронная репликация данных под управлением хост-системы
Данная технология обеспечивает копирование данных головного сервера на удаленный (Рис. 3) под управлением хост-системы (в отличие от простого создания зеркальных копий). Обработка выполняется на том же сервере, где находятся сами тома, поэтому часть ресурсов сервера расходуется на журналы репликации и подобные активности. Эта технология репликации может работать в нескольких режимах: синхронном, асинхронном и адаптивном. В последнем случае обеспечивается автоматическое переключение репликации с синхронного на асинхронный режим, в зависимости от пропускной способности сети.
При репликации под управлением хостсистемы для передачи данных используются, как правило, IP-сети. Хост-система ведет журналы, куда заносятся все произведенные операции записи.
Заполнение журналов начинается с момента, когда по какой-либо причине прерывается передача данных в удаленный центр. Как только требуемая пропускная способность восстановится, хост-система на основе журнала обеспечит пересылку еще не скопированных данных в удаленный центр.
При настройке системы на репликацию только в синхронном режиме необходимо обеспечить требуемую пропускную способность сети. Недостаточная пропускная способность сети может недопустимо ухудшить работу приложений.
Основные преимущества
- Данная технология репликации позволяет точно копировать данные независимо от того, на каких физических устройствах они хранятся.
- Это решение обеспечивает правильность порядка записи, что гарантирует сохранение логики и структуры копированных данных.
- Топология системы не подразумевает обязательного подключения серверов к сети хранения данных (SAN).
- При работе в адаптивном режиме (когда происходит автоматический переход из синхронного режима репликации в асинхронный при недостаточной пропускной способности сети и, соответственно, возникновении очередей) репликация такого типа позволяет успешно решать проблемы сбоев работы сети между вычислительными центрами.
- Эта технология поддерживается как UNIX, так и Windows-серверами.

Основные недостатки
- Поскольку для репликации томов требуется дополнительная обработка данных, вычислительные ресурсы серверов для выполнения производственных задач в определенной степени снизятся (как правило, задача требует не более 5% ресурсов ЦП и памяти).
- В резервный ВЦ потребуется установить сервер, на который будут копироваться данные.
Синхронная репликация данных на базе дискового массива
Здесь используется технология репликации данных средствами физического дискового массива. Специальное программное обеспечение, работающее в составе дискового массива, обеспечивает передачу данных в кэш основного массива, а затем передачу в кэш дискового массива на удаленном узле до подтверждения операции записи головным сервером. При этом на репликацию не тратятся ресурсы сервера, поскольку процесс обслуживается только дисковым массивом. В данной технологии время репликации незначительно возрастает, поскольку операция записи становится двухэтапной.
Эта технология допускает работу в синхронном, асинхронном и адаптивном режимах.
При репликации под управлением дискового массива (Рис. 4) для соединения массивов обычно используется протокол FC, нередко на базе инфраструктуры с мультиплексированием высокой плотности по длине волны (DWDM).
Основные преимущества
- Репликация под управлением дискового массива не создает дополнительной нагрузки на серверы.
- Поскольку все настройки выполняются на самом дисковом массиве, управление проще, чем в решениях под управлением хостсистемы.
- Эту технологию поддерживают как серверы UNIX, так и серверы Windows.
Основные недостатки
- Задержка при записи, появляющаяся с введением двухэтапного процесса передачи в кэш, может повлиять на производительность приложений (даже при небольшом расстоянии между центрами), особенно в тех приложениях, которые предполагают большой объем записи (например, загрузка данных).
- Не все решения этого типа могут обеспечить правильный порядок записи данных в асинхронном режиме.
- В некоторых реализациях репликации на базе дисковых массивов может возникать противоречивость данных при переключении из синхронного режима в асинхронный и обратно.
- Решение этого типа привязывает заказчика к конкретной модели дискового массива. Программное обеспечение по репликации данных одного поставщика не допускает репликации на массивы других поставщиков.
- Все данные, подлежащие репликации, должны храниться в одном массиве.

Варианты с RPO ~ 0 часов (логическое искажение)
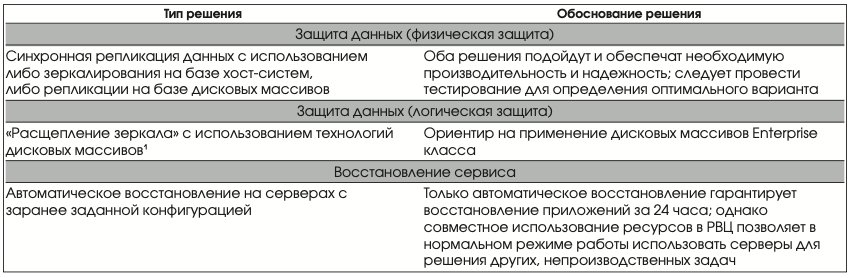
«Расщепление зеркала» с использованием технологических возможностей дисковых массивов
Эта технология применяется для защиты от рисков логических повреждений (Рис. 5). Обычно она комбинируется с одним из решений, описанных выше. Важно понимать, что зеркалирование и репликация не защищают от рисков логического повреждения данных, которые, «как есть», копируются на удаленные узлы.
Дисковые массивы уровня предприятия (Enterprise) способны создавать локально зеркальный образ логического устройства и «расщеплять» зеркало пополам, сохраняя копию тома на фиксированный момент времени. Копия может использоваться для других целей, таких как тестирование приложений или анализ данных. Этот способ можно эффективно использовать для доступа к копии в случае повреждения основных данных.
Такие копии могут создаваться настолько часто, насколько нужно заказчику. Если, например, каждые 60 минут создается копия данных, в случае логического повреждения всегда можно вернуться к данным не более чем 60-минутной давности.
Основные преимущества
• Повторная синхронизация зеркал не создает непосредственной нагрузки на серверы, хотя и может повлиять на ввод-вывод, поскольку потребуется дополнительная пересылка данных внутри дискового массива.
• Зеркальные копии можно использовать для восстановления основного логического тома после физического сбоя.
• Зеркальные копии можно использовать для сопутствующих процессов, например, для генерации отчетов или для резервного копирования.

Основные недостатки
- Поскольку зеркальные копии создаются внутри массива, нет возможности использовать другие, более дешевые массивы для хранения расщепленных зеркальных копий.
- На практике решение такого типа обходится дорого, потому что каждая зеркальная копия основного тома требует того же физического объема устройства хранения, что и сам основной том, включая и незанятое пространство. Если основной LUN (Logical Unit Number) занимает 20 ГБ, а используется из них только 5 ГБ, зеркало все равно будет занимать 20 ГБ.
«Расщепление зеркала» под управлением хост-системы
Этот способ также используется для защиты от логических, а не физических искажений (Рис. 6). Обычно он применяется в сочетании с одним из решений, описанных выше.
Создание зеркальных копий данных под управлением хост-системы с использованием технологий централизованного зеркального копирования реализуется, как правило, в качестве дополнения к менеджеру томов операционной системы.
Как и в случае с массивами, эта технология «расщепляет» зеркало и создает копию основного тома на фиксированный момент времени. Образы данных можно создавать так часто, как потребуется.
Основные преимущества
- С логическими томами зеркальной копии можно работать независимо от физических дисковых массивов. Это позволяет снизить общую стоимость хранения за счет хранения зеркальных копий на альтернативных более дешевых дисковых массивах.
- Зеркальную копию можно использовать для восстановления основного тома в случае его физического сбоя.
- Зеркальные копии можно применять для сопутствующих процессов, например, для генерации отчетов или для резервного копирования.
Основные недостатки
- Решение такого типа обходится дорого, потому что каждая зеркальная копия основного тома требует того же физического объема устройства хранения, что и сам основной том, включая и незанятое пространство. Однако затраты можно сократить за счет использования для хранения зеркальных копий более дешевых дисковых массивов.
- Приложения должны прекратить запись в том в момент создания фиксированного образа. Только в этом случае можно гарантировать, что зеркальный образ будет содержать непротиворечивые и логически неповрежденные данные.

«Мгновенные копии» на основе технологий копирования при записи
Мгновенные копии (Snapshots) – это еще один способ защититься от логического искажения данных, при котором данные копируются под управлением хост-системы (Рис. 7).
Эта технология обычно реализуется как опциональное дополнение к файловой системе сервера. Когда создается мгновенная копия, файловая система генерирует битовый массив, который используется для отслеживания изменений в блоках.
При доступе к мгновенной копии неизмененные блоки читаются, как обычно, из файловой системы, а измененные – с копии первоначальных данных.
Можно делать несколько мгновенных копий. В каждой из них будет свой битовый массив с указателями на блоки, которые претерпели изменения с момента создания копии. Таким образом, требуется всего одна копия измененного блока, каким бы ни было количество созданных мгновенных копий.
Как и в случае с массивами, фиксированные образы можно создавать сколь угодно часто. При этом важно отметить, что создание множества мгновенных копий файловой системы — более практичное решение, потому что для этого требуется совсем немного дискового пространства.
Мгновенные копии можно представить как файловые системы чтения/записи, и при этом они по-прежнему «объединены» со своим основным эквивалентом.
Основные преимущества
- Можно создать много мгновенных копий, заняв лишь незначительную часть дискового пространства (обычно от 5 до 15%).
- Каждая мгновенная копия доступна как независимая файловая система, но осуществить этот доступ может только тот же сервер. Копию можно использовать как «точку отката» в случае логического искажения.
Основные недостатки
- Этот метод пока недоступен на Windowsсерверах.
- Мгновенные копии не защищают от логического искажения, возникшего на уровне ниже файловой системы (например, вследствие ошибки менеджера логических томов или ошибки в канале ввода/вывода SCSI / FC).
- Мгновенные копии не защищают от физического сбоя основной дисковой подсистемы.
- Мгновенные копии увеличивают нагрузку на ЦП и систему ввода/вывода на ведущем сервере. Увеличение составляет, как правило, около 5%, но зависит от уровня активности записи в файловой системе.
Варианты с RPO = 24 часа (физическая потеря данных или логическое искажение)
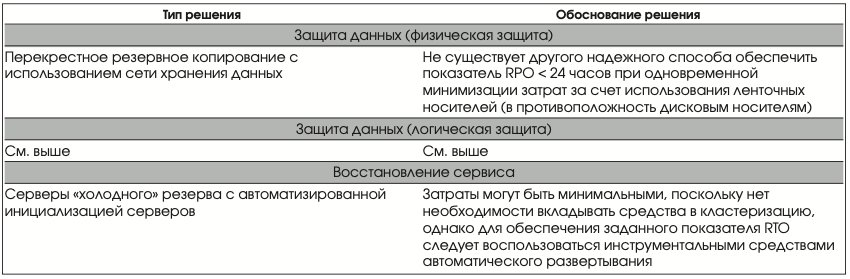
Перекрестное резервное копирование с использованием сети хранения данных
Очевидно, что для реализации решения на удаленной площадке должны храниться носители (например, магнитные ленты) с производственными данными не старше 24 часов.
Для резервного копирования предлагается использовать сеть хранения данных, объединяющую оба центра (Рис. 8). Это наиболее эффективный метод защиты данных путем копирования на ленточные носители, который позволит обеспечить RPO в пределах 24 часов.
Как правило, в решениях такого типа используются выделенные резервные IP-сети и сети хранения данных, объединяющие оба центра. Процесс резервного копирования управляется «медиа» серверами (Media servers). Выделенные
сети для резервного копирования позволяют в условиях штатной работы создавать резервные копии на магнитных носителях в удаленном вычислительном центре. Таким образом, приложения, работающие в любом из центров, будут обеспечены резервными копиями на удаленной территории.
Метаданные, которые хранятся на главном сервере резервного копирования, как правило, защищаются дублированием каталогов в резервном вычислительном центре. Один из серверов хранения данных в РВЦ назначается для исполнения функций главного сервера в случае выхода из строя головного ВЦ.
Основные преимущества
- Если произойдет авария, основная инфраструктура резервного копирования между центрами будет доступна сразу, она образует платформу для восстановления системы.
Основные недостатки
- Пропускную способность сети, соединяющей два центра, придется дополнительно увеличить для передачи трафика данных резервного копирования. Однако при относительно небольших расстояниях в пределах 20 км между вычислительными центрами и при наличии каналов DWDM это не составляет большой проблемы.
- Критическими точками отказа являются «растянутые» IP-сети и сети хранения данных, используемые для резервного копирования. В большинстве случаев такой риск считается приемлемым, потому что сбой одной из этих сетей не повлияет на производственные приложения (они только лишатся возможности создавать резервные копии).
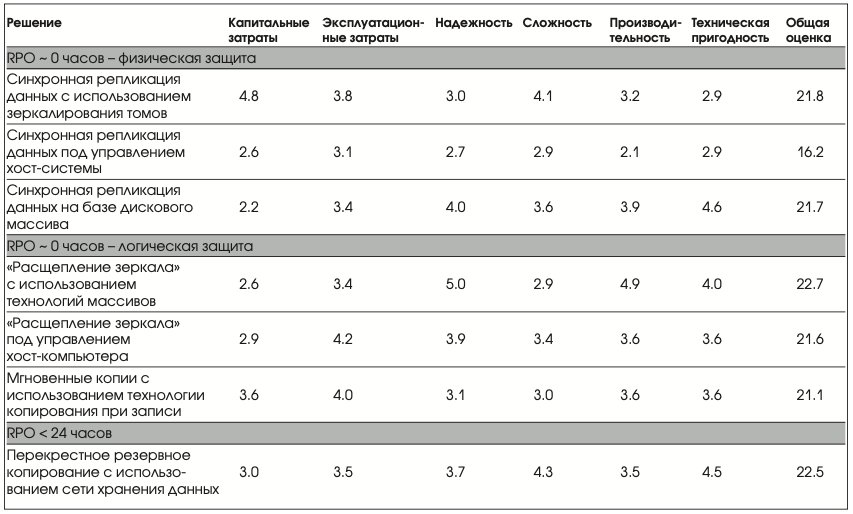
Анализ решений для защиты данных
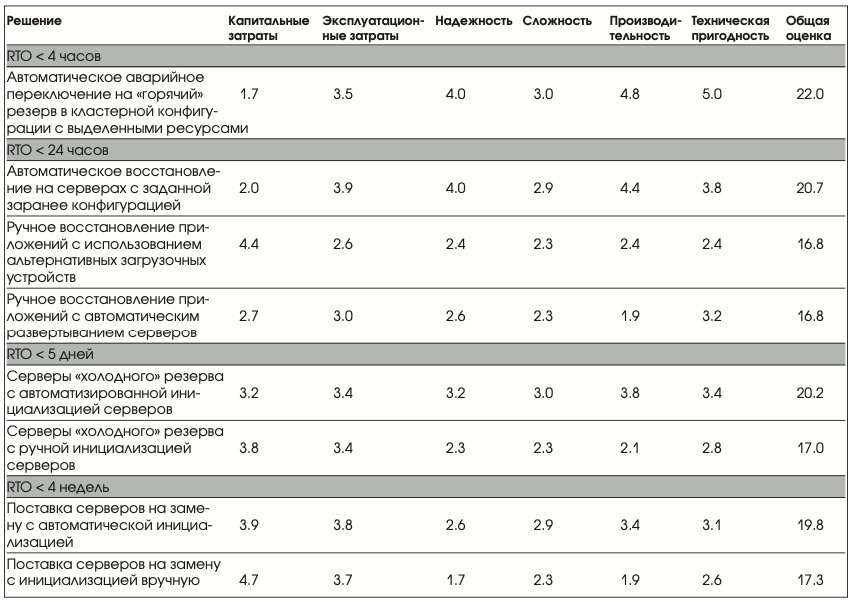
Решения для защиты данных, описанные выше, оценены техническими экспертами компаний VERITAS, «Информационные системы Джет» и группы ИТ-операций ОАО «Вымпелком» применительно к реализации резервного центра ОАО «Вымпелком» по критериям, представленным в Табл.1. По каждому критерию решениям была присвоена оценка от 1 (худшее) до 5 (лучшее).
Технологии защиты систем
Варианты с RTO = 4 часа
Аварийное автоматическое переключение в кластерной конфигурации на «горячий» резервный узел с заранее выделенными ресурсами Восстановить предоставление ИТ-сервиса за четыре часа с момента полного выхода из строя серверного помещения и находящегося там оборудования чрезвычайно сложно. В начале процесса восстановления от 30 до 60 минут потребуется на то, чтобы принять решение о старте процедуры аварийного восстановления, связанной с переключением работы на удаленную резервную площадку. В конце процесса восстановления несколько десятков минут уйдет на проверку восстановленных приложений и непротиворечивости данных.
Ключевая активность в переходный период должна быть направлена на обеспечение быстрого аварийного переключения компонентов инфраструктуры на резервные, восстановление данных и перезапуск приложения. Четырехчасового восстановления (RTO = 4 часа) на практике можно достичь только с помощью средств аварийного автоматического переключения в кластерной конфигурации на «горячий» резервный узел с заранее выделенными ресурсами (Рис. 9).
В такой конфигурации кластерное ПО ведет постоянный мониторинг системы. При обнаружении неисправности производственного сервера объявляется тревога и ответственными специалистами принимается решение о запуске плана аварийного восстановления сервиса на резервной площадке. При соответствующем решении аварийное переключение производственных приложений, данных, пользователей и сопутствующих опорных сервисов производится автоматически.
В чрезвычайной ситуации не рекомендуется использовать аварийное переключение приложений в полностью автоматическом режиме, если нет третьего вычислительного центра, действующего в качестве арбитра для кластера. Не стоит также применять полностью автоматизированное аварийное переключение приложений между основным и резервным центрами в случае аварийных (и сбойных) ситуаций. Следует реализовать процесс, в рамках которого специалисты по ИТ сначала решают вопрос о целесообразности запуска процесса аварийного восстановления, а затем, если принято соответствующее решение, дают команду кластерному программному обеспечению перенести приложения в удаленный центр.
Не рекомендуется допускать, чтобы узлы кластеров совместно использовали ресурсы инфраструктуры обоих центров (это иногда называется «растянутой» кластеризацией). В частности, следует использовать отдельные физические и логические сети, одну для кластеров основного вычислительного центра и одну для кластеров РВЦ. При таком разделении ресурсов исключаются сбои, при которых оба центра данных одновременно оказываются непригодными для работы.
Чтобы выдержать RTO=4 часа, должны быть заранее выделены необходимые ресурсы для аварийного поднятия приложений в РВЦ, и на них заранее должны быть установлены операционные системы и другое базовое программное обеспечение. Сценарий восстановления после чрезвычайной ситуации может допускать консолидацию приложений на серверах, но для снижения рисков к минимуму такие меры необходимо тщательно планировать.
Еще один фактор, влияющий на успех аварийного восстановления, — обеспечение требуемой производительности приложений в условиях чрезвычайной ситуации. Для некоторых из них может быть допустима сниженная производительность в условиях ЧС, это позволит уменьшить требуемые ресурсы резервного серверного комплекса и тем самым добиться экономии средств.
Корпоративные многодоменные серверы позволяют динамично выделять для доменов вычислительные ресурсы. В таких серверах можно изначально конфигурировать домены минимальной величины, чтобы создать платформу для переноса на них производственных приложений при ЧС. Свободные вычислительные ресурсы в штатном режиме используются для некритичных задач, связанных с тестированием и разработкой.
После запуска процедуры аварийного восстановления система реконфигурируется, и необходимые вычислительные ресурсы автоматически передаются домену, на который аварийно переключается производственная задача.
Основные преимущества
- Такое решение минимизирует потребность во вмешательстве операторов, что значительно снижает риски ошибочных действий в напряженный период сразу после аварии.
Основные недостатки
- Для обеспечения быстрого восстановления необходимо выделить сервер «горячего» резерва, его конфигурация должна строго контролироваться: все изменения, внесенные в конфигурации серверов основного ВЦ, надо произвести и в РВЦ.
- Решение такого типа требует наличия в РВЦ актуальной копии данных; то есть приложения, защищаемые таким путем, должны быть развернуты на серверах, подключенных к сети хранения данных.
Варианты с RTO = 24 часа
Автоматическое восстановление на заранее сконфигурированных серверах двойного назначения.
При RTO = 24 часа нет необходимости использовать специальное программное обеспечение для аварийного автоматического переключения приложений. Однако кластерное ПО целесообразно использовать для управления процессом остановки непроизводственных сервисов и запуска производственных приложений на серверах РВЦ.
Как и в предыдущем варианте, нежелательно совместное использование каких-либо ресурсов опорной ИТ-инфраструктуры обеих площадок разнесенными кластерными узлами, т.е. следует избегать топологии «растянутого» кластера. В частности, надо использовать отдельные физические и логические сети, одну для кластеров основного вычислительного центра и другую для кластеров резервного вычислительного центра.
Стоимость решения такого рода можно снизить, консолидируя приложения в РВЦ на меньшем количестве серверов, чем в основном центре.
Эту возможность необходимо тщательно планировать, чтобы свести риски к минимуму.
Основные преимущества
- Данное решение позволяет быстро произвести аварийное переключение при минимальном вмешательстве операторов.
- В нормальном режиме работы их можно направить на решение других задач с низким приоритетом.
Основные недостатки
- Некритичные приложения, которые выполняются в РВЦ в нормальном режиме, будут остановлены в случае чрезвычайной ситуации.
- На серверах РВЦ должны быть установлены те же версии операционных систем с теми же дополнениями и тем же базовым программным обеспечением, что и в производственной конфигурации. Это ограничивает возможности использования резервных серверов в штатном режиме.
- Необходимо выстроить процесс, который обеспечит качественный контроль изменений конфигураций серверов: все изменения, внесенные в ресурсы в основном ВЦ, должны строго отслеживаться и в резервном ВЦ.
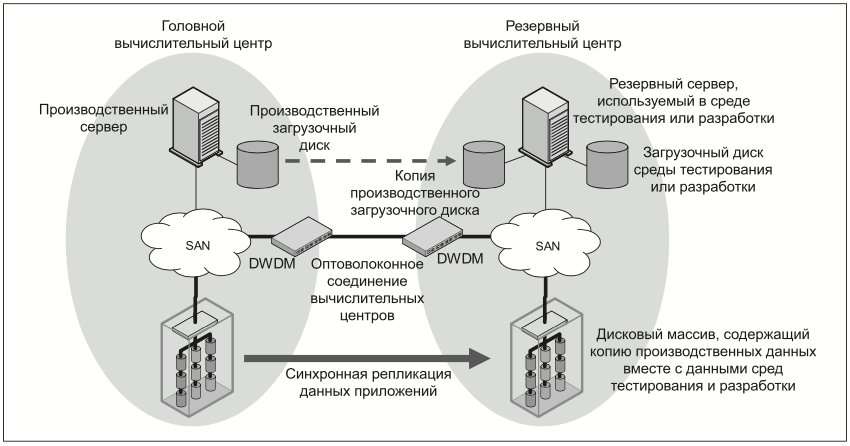
Восстановление приложений вручную с резервных загрузочных дисков
Приложения могут быть перенесены за 24 часа в РВЦ с помощью резервных загрузочных дисков (Рис. 10). В этом случае в нормальном режиме на резервных узлах могут работать собственные приложения и операционные системы, а в чрезвычайной ситуации узлы перезагружаются с использованием того же загрузочного образа, что и в основном центре.
Данный способ более рентабелен, поскольку нет необходимости приобретать программное обеспечение для кластеризации, а серверы для восстановления в нормальном режиме можно использовать для тестирования и разработки. Однако это решение все равно требует репликации производственных данных в РВЦ.
Недостаток этой технологии заключается в относительно сложном процессе эксплуатации предлагаемого решения. Оно окажется неэффективным, если не соблюдать процессы оперативного управления, особенно в части управления изменениями.
Регулярное тестирование решений такого рода гарантирует их эффективность в конкретных реализациях. Необходимо также следить за тем, чтобы аппаратный комплекс в РВЦ строго повторял конфигурацию аппаратных средств основного ВЦ.
Основные преимущества
- Позволяет гибко использовать серверы резервного вычислитеного центра в штатном режиме работы организации.
Основные недостатки
- Требует жесткой процедуры контроля изменений, гарантирующей регулярное обновление резервных загрузочных дисков в соответствии с изменениями, которые вносятся в корневые файловые системы в основном центре.
- Требует наличия четких регламентов аварийного восстановления, обеспечивающих корректное восстановление работы приложений после чрезвычайной ситуации.
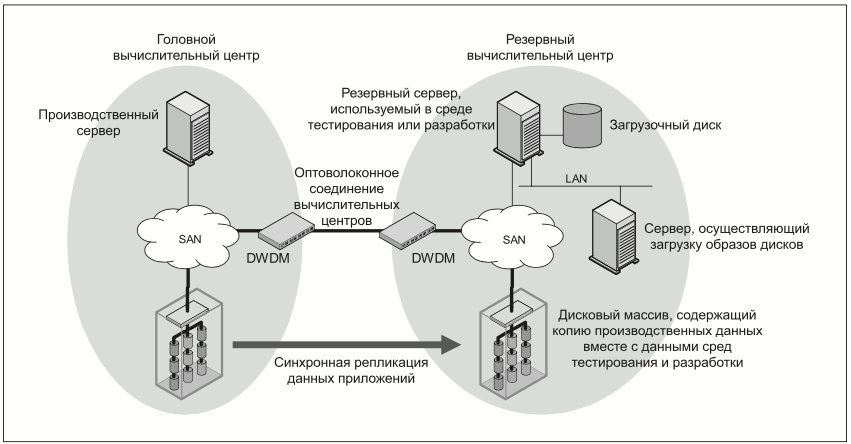
Восстановление приложений вручную с использованием автоматической инициализации сервера (Automated Server Provisioning)
Существующие технологии дают возможность конфигурировать серверы с помощью средств автоматической инициализации, используя образы, хранящиеся на выделенном узле. Они по этому запросу автоматически разворачивают операционные системы и сопутствующее программное обеспечение на узлах сети. Данная технология позволяет в случае чрезвычайной ситуации автоматически развернуть серверные ресурсы резервного ВЦ (Рис. 11).
Аппаратные ресурсы, зарезервированные для аварийного восстановления в случае ЧС, должны постоянно находиться в РВЦ. В штатном режиме их можно использовать для низкоприоритетных задач. В чрезвычайной ситуации серверы, предназначенные для аварийного восстановления, перезагружаются, и на них через IP-сеть передаются образы операционной системы. После этого серверы получают доступ к томам данных, скопированным из основного ВЦ, и сервис возобновляет работу на резервной площадке.
Этот способ рентабелен, поскольку нет необходимости приобретать программное обеспечение для кластеризации, а серверы, предназначенные для аварийного восстановления, в штатном режиме можно гибко использовать для тестирования и разработки.
Данное решение требует репликации производственных данных в РВЦ.
Недостаток: для средства автоматической инициализации потребуется приобрести соответствующее аппаратное и программное обеспечение. Операционные процессы поддержки и использования этого решения менее сложны, чем при использовании резервных загрузочных дисков. Решение будет неэффективным, если не соблюдать процессы оперативного управления, особенно это касается управления изменениями.
Решения такого рода следует регулярно тестировать, что будет гарантировать их эффективность в конкретных реализациях. Необходимо также следить за тем, чтобы аппаратный комплекс в резервном вычислительном центре повторял конфигурацию аппаратных средств основного ВЦ.
Основные преимущества
• Позволяет в штатном режиме гибко использовать серверы, предназначенные для аварийного восстановления.
Основные недостатки
- Требует жестких процедур контроля изменений, которые гарантируют актуальность загрузочного образа на сервере инициализации. (Некоторые автоматические средства инициализации можно конфигурировать так, чтобы они регулярно получали новый образ с основных серверов).
- Требует наличия четких регламентов, гарантирующих правильное восстановление после чрезвычайной ситуации.
- Требует дополнительного аппаратного обеспечения для серверов инициализации.
Варианты с RTO = 5 дней
Серверы «холодного» резерва с автоматической инициализацией серверов
Чтобы обеспечить восстановление в пределах пяти дней, можно применить автоматическую инициализацию серверов (см. выше). Однако при пятидневном запасе времени на восстановление работы приложения можно использовать серверные ресурсы, предоставленные поставщиком по согласованной цепи, либо взятые со склада организации.
Как правило, в данном варианте клиенты заключают договор с поставщиком аппаратного обеспечения, гарантирующий им поставку необходимых ресурсов в установленный срок. Серверы часто берутся в аренду.
Такой способ выгоден, поскольку не требует покупки аппаратного обеспечения до тех пор, пока не возникнет чрезвычайная ситуация. Для реализации этого решения производственные данные должны находиться в РВЦ, как правило, в виде резервной копии на ленточных носителях.
Тем не менее, все необходимое аппаратное и программное обеспечение для автоматической инициализации серверов стоит приобрести заблаговременно. Без него восстановить работу серверного комплекса в течение пяти дней будет очень сложно. Это решение требует соблюдения процессов оперативного управления, особенно управления изменениями.
Для обеспечения гарантии эффективности решения необходимо регулярно проводить его тестирование.
Основные преимущества
- Данное решение не требует заблаговременной покупки серверов для восстановления до тех пор, пока не возникнет реальная чрезвычайная ситуация.
Основные недостатки
- Требует жестких процедур контроля изменений, которые гарантировали бы наличие актуального загрузочного образа на сервере инициализации (средства автоматической инициализации можно конфигурировать так, чтобы они регулярно получали новый образ с основных серверов).
- Требует жестких процедур, гарантирующих правильное восстановление после чрезвычайной ситуации.
- Требует дополнительного аппаратного и программного обеспечения для серверов инициализации.
Серверы «холодного» резерва с ручной инициализацией серверов
В этом решении используются, по существу, те же принципы, что и в предыдущем, но средство автоматической инициализации не предусмотрено.
Здесь нужны жесткие оперативные процедуры, гарантирующие точное описание ручного конфигурирования серверов и их своевременную поставку. После загрузки основной операционной системы все остальные данные восстанавливаются с ленточных носителей.
Это решение не будет эффективным, если не соблюдать процессы оперативного управления. В частности, следует регулярно создавать резервные копии операционных систем основного ВЦ, чтобы в чрезвычайной ситуации иметь в наличии копию состояния системы на основном сервере. Необходимо хранить резервные копии в РВЦ и вести их каталог для упрощения доступа.
Основные преимущества
- Низкие затраты, поскольку до наступления чрезвычайной ситуации дополнительные серверы не нужны.
Основные недостатки
- Требуются четко документированные и осмысленные процедуры инициализации серверов.
Варианты с RTO = 4 недели
Поставка серверов на замену с автоматической инициализацией
Возобновление сервисов в течение четырех недель с момента возникновения чрезвычайной ситуации предполагает наличие достаточного времени для закупки или взятия в аренду новых серверов и подготовки их к работе после получения от поставщика. Чтобы ускорить процесс инсталляции, можно также использовать средства автоматической инициализации для конфигурирования новых серверов.
Необходимо следить за тем, чтобы у поставщика аппаратного обеспечения на складе всегда было оборудование, которое может потребоваться в чрезвычайной ситуации. В договоре с поставщиком должна гарантироваться поставка всех необходимых компонентов в течение трех недель.
Для автоматической инициализации нужно соответствующее аппаратное и программное обеспечение. Это решение также требует соблюдения процессов оперативного управления. В частности, необходимо регулярно создавать резервные копии операционных систем основного ВЦ, чтобы в чрезвычайной ситуации иметь актуальную копию состояния системы на основном сервере. Необходимо хранить резервные копии в РВЦ и вести их каталог для упрощения доступа.
Основные преимущества
- Не требует покупки серверов для восстановления до тех пор, пока не возникнет чрезвычайная ситуация.
Основные недостатки
- Требует жестких процедур контроля изменений, которые гарантировали бы наличие актуального загрузочного образа на сервере инициализации.
- Требует жестких процедур, гарантирующих правильное восстановление после чрезвычайной ситуации.
- Требует дополнительного аппаратного и программного обеспечения для серверов инициализации.
Поставка серверов на замену с инициализацией вручную
В ряде случаев можно добиться времени восстановления менее четырех недель и без использования инструментальных средств автоматического развертывания.
Основные преимущества
- Низкие затраты, поскольку до наступления чрезвычайной ситуации дополнительные серверы не нужны.
Основные недостатки
- Требуются четко документированные и осмысленные процедуры инициализации серверов.
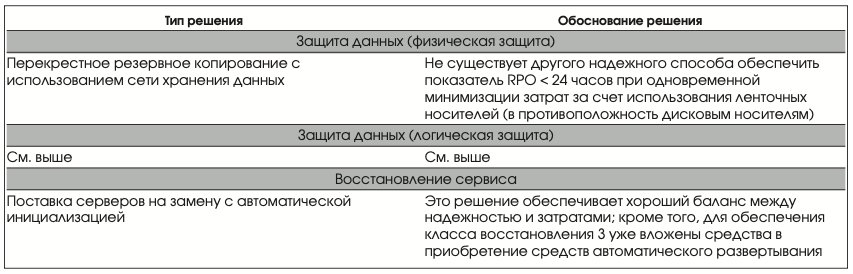
Анализ решений для восстановления сервисов
Различные решения для защиты систем, описанные выше, были оценены по критериям, представленным в Табл.2. По каждому критерию решениям была присвоена оценка от 1 (худшее) до 5 (лучшее).
Оценки, приведенные в Табл. 2, даны техническими экспертами компаний VERITAS, «Информационные системы Джет» и группы ИТ-операций ОАО «Вымпелком».
Обеспечение непрерывности ИТ-сервисов в случае ЧС
Ниже приведены примеры возможных технологий по обеспечению непрерывности ИТ-сервисов для поддержания четырех классов восстановления после бедствия. Эти технологии отобраны на основе анализа, о котором шла речь в предыдущих разделах, и рассчитаны на достижение целевых показателей восстановления (RTO и RPO) соответствующего класса.
Класс восстановления 1 Показатели восстановления
- Целевое время восстановления — 4 часа;
- целевая точка восстановления ~0 часов (минимальная потеря данных).
Решения, обеспечивающие этот класс восстановления, представлены в Табл. 3.
Класс восстановления 2 Показатели восстановления
- Целевое время восстановления < 24 часов;
- целевая точка восстановления ~0 часов (минимальная потеря данных).
В Табл. 4 приведены решения, обеспечивающие этот класс восстановления.
Класс восстановления 3 Показатели восстановления
- Целевое время восстановления < 5 дней; • целевая точка восстановления < 24 часов.
В Табл. 5 приведены решения, обеспечивающие этот класс восстановления.
Класс восстановления 4 Показатели восстановления
- Целевое время восстановления — 4 недели (целевое значение);
- целевая точка восстановления < 24 часов.
В Табл. 6 приведены решения, обеспечивающие этот класс восстановления.
The Business Continuity Institute
Институт непрерывности бизнес-процессов (The Business Continuity Institute, BCI) основан в 1994 г. в Великобритании с целью поддержки высоких этических норм при оказании услуг в области планирования непрерывности бизнеса, продвижения высших профессиональных стандартов, развития идей, направленных на повышение жизнеспособности бизнеса, обеспечения непрерывности деятельности. Среди основных направлений деятельности этой некомерческой организации – разработка стратегий непрерывности, реакция на чрезвычайные ситуации, разработка и внедрение планов непрерывности бизнеса, поддержка и тестирование планов непрерывности бизнеса. По этим и другим вопросам специалисты, входящие в эту международную некоммерческую организацию, проводят консультации.
BCI объединяет уже свыше двух тысяч сертифицированных профессионалов в области обеспечения непрерывности бизнеса из более чем 50 стран, предоставляя им возможность общаться, обмениваться опытом с коллегами, занимающимися обеспечением непрерывности и аварийным восстановлением. В 21 стране, включая Россию, есть региональные представители института.
Институт непрерывности бизнес-процессов участвует в организации различных мероприятий, посвященных аварийному восстановлению и обеспечению непрерывности деятельности.
- Ежегодно с момента своего основания институт проводит BCI International Symposium. Этот международный форум – замечательная возможность консультантам, живущим и работающим в различных странах мира, обсудить актуальные проблемы, такие как противоречия между теорией и практикой управления в кризисной ситуации, новые риски, методики и критерии оценки планов обеспечения непрерывности и др.
- Business Continuity EXPO – одна из крупнейших в мире и самая крупная в Европе выставка, посвященная аварийному восстановлению и обеспечению непрерывности деятельности. Десятки крупнейших производителей программного и аппаратного обеспечения, страховые и сервисные компании, консультационные фирмы ежегодно представляют здесь последние достижения в этой области. Параллельно с выставкой проводятся тематические конференции по различным аспектам данного рода деятельности.
- Business Continuity Awareness Weeks – регулярно проводимые по всему миру мероприятия, в которых участвуют специалисты BCI, работающие в разных странах. Это своеобразные акции, в рамках которых члены BCI через сайт BCI распространяют наглядные материалы, справочную литературу и методические рекомендации, призванные привлечь внимание специалистов и руководителей компаний и предприятий к проблемам управления рисками, подготовки к наихудшему сценарию развития событий в случае аварии, вопросам соблюдения законодательных требований в области надежности и безопасности и т.п.
- Business Continuity Awards – ежегодное торжественное мероприятие, на котором по нескольким номинациям отмечаются выдающиеся достижения в области обеспечения непрерывности бизнес-процессов.
Институт активно участвует в разработке рекомендаций и стандартов обеспечения непрерывности бизнес-процессов.
- 2002 год. Рекомендации по применению правильных методов (Good Practice Guidelines). Документ разработан членами BCI, опубликован в 2002 г. Получил поддержку и одобрение нескольких ключевых государственных органов Великобритании. Распространяется бесплатно.
- 2003 год. Общедоступная спецификация No 56 Британского Института Стандартов (British Standard Institute Publicly Available Specification #56). Документ разработан при участии BCI на базе Good Practice Guidelines. Опубликован в 2003 г.
- 2005 год. Создание полноценного стандарта обеспечения непрерывности. BCI принимает активное участие в дальнейшем развитии PAS 56.
- В ближайшие годы предполагается утверждение аналога PAS 56 в качестве международного ISO-стандарта. Помощь в разработке государственных стандартов управления рисками и обеспечения непрерывности Австралии, Новой Зеландии, Сингапура, Китая. Унификация подходов к обеспечению непрерывности Великобритании и США.
- BCI разработал собственную образовательную программу.
- Основу образовательной программы составляет документ «Рекомендации по применению правильных методов» (Good Practice Guidelines), а реализация этой программы направлена на развитие и распространение данного документа, включая перевод на другие языки.
- Институт разработал и бесплатно распространяет типовой учебный план, а также проводит оценку существующих учебных курсов различных образовательных учреждений по тематике обеспечения непрерывности на соответствие «Рекомендациям по применению правильных методов». Такая оценка, во-первых, свидетельствует о том, что содержание курса соответствует методике и стандартам, разработанным институтом, а, во-вторых – что данный курс содержателен и нагляден.
- Институт непрерывности бизнесс-процессов оказывает поддержку своим членам, желающим углублять знания и навыки, предоставляя возможность участвовать в программе менторского обучения, как в качестве учеников, так и в качестве наставников. Участие в данной программе учитывается при прохождении сертификации.
- Членами института ведется работа по составлению и обновлению словаря терминов в области обеспечения непрерывности, аварийного восстановления и управления в кризисной ситуации. Эта работа координируется с аналогичными проектами в других организациях, поэтому имеет международное значение.
Организационная структура института довольно проста. BCI Forum Ltd является некоммерческой самоуправляемой организацией, основным источником дохода служат членские взносы. Она имеет торговое подразделение Business Continuity Institute Ltd, основным источником доходов которого являются пожертвования спонсоров, а также размещение рекламы и взносы корпоративных партнеров.
Одну из важнейших целей своей деятельности институт видит в обеспечении качества предоставляемых услуг. Для достижения этой цели была разработана и внедрена собственная схема сертификации. Она обеспечивает структурированный подход к оценке квалификации специалистов в области обеспечения непрерывности и аварийного восстановления и устанавливает критерии оценки передового опыта, а также стимулирует процессы самосовершенствования и овладения дополнительными навыками.
Сертификация основана на 10 стандартах, известных как «Стандарты сертификации для профессионалов в области обеспечения непрерывности» (Certification Standards for Business Continuity professionals), признанных международным сообществом. Они охватывают все направления, необходимые для осуществления эффективного управления непрерывностью деятельности.
1. Инициация и руководство BC (Initiation and Management);
2. Анализ влияния на бизнес (Business Impact Analysis);
3. Оценка и управление рисками (Risk Evaluation and Control);
4. Разработка BC-стратегий (Developing Business Continuity Management Strategies);
5. Оперативное реагирование и первичные действия (Emergency Response and Operations);
6. Разработка и реализация планов (Developing and Implementing Business Continuity and Crisis Management Plans);
7. Обучение и тренировки (Awareness and Training Programmes);
8. Поддержка и обновление планов (Maintaining and Exercising Business Continuity and Crisis Managements Plans);
9. Связь с общественностью в кризисной ситуации (Crisis Communications);
10. Работа с внешними структурами и организациями (Co-ordination with External Agencies).
Еще одним средством обеспечения качества служит свод правил поведения и деятельности профессионалов в области обеспечения непрерывности (Code of Practice and Ethics for Business Continuity Practitioners). Каждый член института при вступлении дает письменное обещание придерживаться данных правил в своей деятельности.
Действительные члены института могут иметь один из четырех уровней:
- Первый уровень – ASSOCIATE (ABCI) – начинающий специалист, чья деятельность связана с обеспечением непрерывности или близкими вопросами. Изучение всех 10 стандартов сертификации.
- Второй уровень SPECIALIST (SBCI) – профессиональная деятельность в области, связанной с обеспечением непрерывности. Двухлетний опыт работы в области, связанной с обеспечением непрерывности. Понимание, не менее 4 стандартов сертификации.
- Третий уровень MEMBER (MBCI) – практикующий специалист в области обеспечения непрерывности. Двухлетний опыт работы в области, связанной с обеспечением непрерывности, понимание всех 10 стандартов сертификации.
- Четвертый уровень FELLOW (FBCI) – практикующие специалисты в области обеспечения непрерывности руководящего звена. Пятилетний опыт работы в области, связанной с обеспечением непрерывности, доскональное знание всех 10 стандартов сертификации.

