 Подписаться
Подписаться Читать в телеграм
Читать в телеграм

Для повышения эффективности хранения данных в облаке в большинстве случаев используется многоуровневая система. Суть этого подхода состоит в том, что далеко не вся информация одинаково востребована на текущий момент времени, активность доступа может варьироваться в очень широком диапазоне. В случае использования многоуровневой (иерархической) системы мы можем получить реальную экономию от использования более дешевых ресурсов хранения для малоактивных и маловостребованных данных. Если заранее известно, что та или иная информация будет необходима в ближайшее время, можно вручную или автоматически по расписанию настроить уровень хранения таким образом, чтобы он максимально соответствовал планируемой нагрузке. Это может быть актуально для построения различных отчетов, например годовых, когда малоактивные данные девятимесячной давности, лежащие на низкоскоростном уровне с невысокой стоимостью, вдруг становятся необходимы, а производительности их текущего уровня хранения не хватает для быстрого составления отчета.
решение для облачного хранения данных на базе распределенного файлового кластера HNAS имеет широкий набор характеристик. Он позволяет строить гибкие и легко масштабируемые решения для создания больших, территориально распределенных хранилищ, максимально эффективно использовать имеющееся оборудование и в то же время обеспечивать оптимальную защиту информации
Еще две важные особенности облачного хранилища – это его отказо- и катастрофоустойчивость. Почему мы разделяем эти два понятия? Как правило, под отказоустойчивостью понимается способность облачного хранилища продолжать выполнять свои функции и задачи при выходе из строя одного или нескольких программных или аппаратных компонентов. Степень ущерба для производительности доступа к данным зависит от дизайна решения. Катастрофоустойчивость облачного хранилища подразумевает его способность продолжать выполнять свои функции и задачи при выходе из строя ЦОД целиком. Причинами таких масштабных аварий могут быть природные или техногенные катаклизмы. Последний масштабный пример техногенной катастрофы на моей памяти – это выход из строя электрических подстанций в Москве в мае 2005 года. Многие заказчики, у которых основной и резервный ЦОД находились в аварийных районах, на сутки потеряли доступ к данным. Если вспомнить природные катаклизмы, наводнение на Дальнем Востоке – актуальный пример, так как затопленной оказалась часть большого региона. Поэтому при планировании катастрофоустойчивых хранилищ всегда нужно принимать во внимание аварии, которые могут затронуть огромные площади. Для защиты от таких катастроф строят решение с репликацией между тремя ЦОД. Первые два основных дата-центра находятся на расстоянии менее 100 км друг от друга, и между ними настраивается синхронная репликация. Расстояние между ЦОД выбирается исходя из требований облачного хранилища к максимальной задержке операций ввода/вывода. При этом авария одного из дата-центров не приведет к потере данных. Третий ЦОД, как правило, располагается в другом регионе, и между ним и двумя основными настраивается асинхронная репликация. В случае недоступности остальных дата-центров, облачное хранилище сможет продолжить предоставлять доступ к данным без последних изменений, которые не успели реплицироваться из-за аварии.
Используя новейшие технологии репликации, кроме создания катастрофоустойчивых облачных хранилищ, можно обеспечить мобильность данных или реализовать решение, когда два дата-центра работают в Active-Active режиме. В первом случае появляется возможность переносить ресурсы с одного ЦОД в другой без прекращения доступа к информации. Это позволяет гибко перераспределять нагрузку или осуществлять миграцию части данных при выполнении сервисных работ в одном из дата-центров. Во втором случае мы избавляемся от основного недостатка катастрофоустойчивых решений – Active-Passive-подхода, когда часть ресурсов находится в ждущем режиме (Standby) и не используется для обслуживания ввода/вывода. Таким образом, катастрофоустойчивая конфигурация облачного хранилища совместно с режимом Active-Active между ЦОД позволит эффективно использовать cloud-хранилище, сохраняя максимальную защищенность решения. Для создания действительно катастрофоустойчивого облачного хранилища с конфигурацией Active-Active между ЦОД мы предлагаем решение на базе территориально распределенного файлового кластера HNAS SyncDR. Схема подобной системы на базе гипервизора VMware приведена на рис. 1.
Рис. 1. Схема построения территориально распределенного файлового кластера
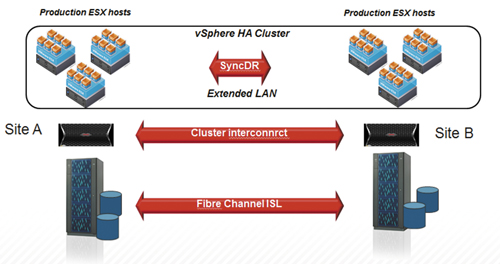
Данное решение использует синхронную репликацию между ЦОД. Таким образом, сбой любого дата-центра не приводит ни к потере данных, ни к прекращению доступа к ним. В основе решения лежит синхронная репликация TrueCopy между блочными системами хранения нашей компании. В зависимости от требований к производительности и масштабируемости Data Warehouse в конфигурации могут использоваться как модульные системы хранения Hitachi Unified Storage 100, так и системы корпоративного уровня Hitachi Unified Storage VM и Virtual Storage Platform. Поверх блочного уровня хранения развертывается распределенный между двумя площадками файловый кластер на базе файловых модулей HNAS. Таким образом, предоставляется единый для двух площадок пул файловых ресурсов для гипервизоров и вышестоящего программного обеспечения.
Сегодня бизнес-процессы требуют эффективности в хранении данных, отказоустойчивости при доступе к ним, мобильности ресурсов и предоставления их по требованию. Все эти задачи в полном объёме решает облачный подход к хранению данных
Для создания более сложных решений с тремя ЦОД файловый кластер HNAS поддерживает асинхронную репликацию на другой HNAS, который может быть расположен в тысячах километров от двух основных дата-центров.
Итак, решение для облачного хранения данных на базе распределенного файлового кластера HNAS имеет широкий набор характеристик. Он позволяет строить гибкие и легко масштабируемые решения для создания больших, территориально распределенных хранилищ, максимально эффективно использовать имеющееся оборудование и в то же время обеспечивать оптимальную защиту информации.

