 Подписаться
Подписаться Читать в телеграм
Читать в телеграм
Традиционно в ИТ-инфраструктуре дата-центра выделялись три звена: сеть, серверы и системы хранения. Для каждого отдельного приложения использовалась своя группа оборудования. Такой подход был малоэффективен для решения большинства прикладных задач и затруднял повторное использование оборудования после окончания жизненного цикла приложения (в случае спонтанно или периодически возникающих бизнес-процессов). Миграция приложения из одного дата-центра в другой была и вовсе невозможна без длительной, часто многомесячной процедуры предварительной подготовки.
Все изменилось, когда около 10 лет назад появились технологии, позволяющие виртуализировать сначала серверы, а затем и системы хранения. Виртуализация позволяет использовать один блок оборудования для выполнения нескольких вычислительных задач и тем самым увеличивает эффективность ИТ-ресурсов. Но что гораздо важнее, она обеспечивает возможность переконфигурирования системы, освобождение вычислительных мощностей, когда задача теряет актуальность, их повторное использование под другую задачу и т.д. Виртуализация добавляет новый уровень абстракции в ИТ-инфраструктуру. Мы больше не думаем о том, какой процессор в нашей системе, какие модели памяти, дисков используются для хранения и обработки данных. Система виртуализации дает нам виртуальные компоненты, из которых мы строим нашу платформу для работы приложения. Мы не так зависим от циклов замены и обновления оборудования, они могут происходить незаметно для нас. Если мы добавим к такой виртуализированной инфраструктуре автоматизацию всех выполняемых действий, мы получим облачную платформу. Частное облако, виртуальное частное, публичное – неважно, это только модели использования, по большей части они зависят от выстроенных организационных процессов и мало влияют на саму инфраструктуру (конечно же, кроме подсистемы безопасности).
Наше приложение теперь не зависит от «физики». Но является ли оно независимым от облачной платформы? И для чего может потребоваться такая независимость?
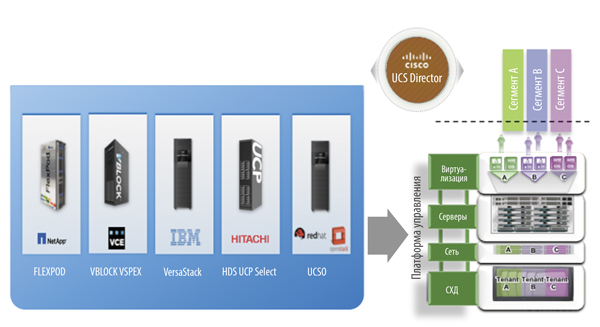
Рис. 1. Интегрированные блоки под управлением UCS Director, которые позволяют унифицировать подход к построению вычислительной платформы
Когда абстракции недостаточно
Давайте рассмотрим структуру приложения (application). Если отвлечься от деталей работы тех или иных программ, приложение можно представить как систему, состоящую из вычислительных нагрузок и сетевых сервисов между ними. Сетевые сервисы – вот то, что делает из группы серверов и виртуальных машин законченную ИТ-систему. Их правильная реализация и конфигурация также важны для работы приложения, как и настройки серверов, виртуальных машин и программ внутри него.
Вычислительная нагрузка (workload) в данном контексте – это программа, работающая на физическом или виртуальном сервере. Независимо от варианта реализации она предъявляет требования к 4 характеристикам: к процессорной мощности сервера, оперативной памяти, СХД и системе сетевого взаимодействия. Программа взаимодействует с другими программами на 7-м уровне сетевой модели ISO и отвечает за реализацию конкретных действий: за хранение и обработку данных. Например, web-сервер отвечает на запросы от пользователей по протоколу HTTP и при необходимости запрашивает данные у сервера приложений. Сервер приложений собирает и подготавливает информацию для ответа на запрос пользователя, для этого он может использовать другие компоненты приложения: сервер баз данных, сервер аутентификации и т.д.
Сетевые сервисы работают на уровнях с 7-го по 2-й сетевой модели ISO и отвечают главным образом за передачу сетевого трафика между отдельными вычислительными нагрузками, составляющими приложение. Здесь выполняются маршрутизация, фильтрация трафика, балансировка нагрузки, шифрование и т.д. Способы реализации этих сервисов могут быть разными, традиционный вариант – отдельные аппаратные устройства. Также в последнее время приобретают популярность программные сетевые модули, работающие внутри отдельных виртуальных машин, например, виртуальный маршрутизатор Cisco CSR 1000v, балансировщик нагрузки Citrix NetScaler, шлюз безопасности Sourcefire и т.д.
А теперь вернемся к вопросу, для чего может потребоваться перенос приложения из одной инфраструктуры в другую. Рассмотрим наиболее простой пример – его начальное развертывание. Можно не тратить время на установку и настройку всех программ, конфигурацию сетевых сервисов, а просто взять готовый «контейнер», собранный для нас поставщиком в его центре разработки, и «развернуть» его поверх виртуализированной инфраструктуры. Но есть одна проблема – реализация сетевых сервисов и настройки сетевой части отличается в разных дата-центрах. Это значит, что нужен еще один уровень абстракции, позволяющий реализовать общий подход к конфигурированию сети между отдельными программами внутри приложения.
Справедливости ради нужно отметить, что производители средств серверной виртуализации уже давно предпринимают попытки решения этой задачи. Основной предлагаемый подход базируется на концепции так называемых контейнеров приложений (application containers). Суть в том, что если все виртуальные машины и сетевые сервисы могут работать внутри платформы виртуализации, то можно использовать различные виртуальные сетевые контейнеры при одних и тех же настройках физической сети. Эта идея имеет множество ограничений, но в частном случае является хорошим решением для небольших, мало нагруженных приложений, состоящих только из виртуальных машин. Из последних новинок в этой области можно выделить продукт Cisco Virtual Application Container Service (VACS), он позволяет взаимодействовать приложениям, работающим на разных платформах гипервизоров. Функциональность маршрутизатора CSR 1000v дает возможность пользователям виртуальной среды терминировать MPLS-сеть (Multiprotocol Label Switching) внутри контейнера с приложением. Тем самым достигаются несколько целей: снимается нагрузка с пограничных маршрутизаторов ЦОД, а у пользователя приложения появляются гибкость и дополнительный контроль того, как его приложение связано с внешним миром.
Другой вариант решения задачи динамического изменения сетевых настроек – это модель оверлейных сетей, также предлагаемая некоторыми производителями платформ виртуализации. Ее суть состоит в допущении, что физическая сеть является идеальной, т.е. обладает неограниченно высокой пропускной способностью и полносвязной топологией. Оверлейные сети полностью абстрагируют сетевой трафик от физической сети и создают виртуальные туннели между приложениями, куда и встраивают виртуальные сетевые сервисы. Концепция выглядит многообещающей, но мы живем в реальном мире, и идеальных сетей в нем не бывает. Физическая сеть имеет свои ограничения, к тому же в ней могут случаться поломки, и по факту при таком подходе администратор вынужден отвечать за две сети вместо одной. Причем между ними нет никакой связи, кроме того, что одна работает поверх другой, даже инструменты для администрирования и поиска проблем полностью различаются.
Архитектура сети, ориентированная на приложения
Описанные подходы более-менее работают, если дело касается «статических» приложений. Но современный мир не стоит на месте, и бизнес ставит новые задачи перед ИТ. Зачастую они приводят к необходимости перенастройки приложения на лету или вообще к его переносу в другой дата-центр. Таких задач появляется все больше, самые распространенные из них:
- поддержка DevOps модели разработки новых клиентских сервисов. Разработка продукта идет непрерывно, и периодичность появления новых релизов может составлять несколько недель и даже дней;
- обеспечение восстановления после сбоев (Disaster Reco-very). При сбое в основном ЦОД приложение должно переехать в резервный и восстановить там свою работу;
- рост нагрузки при ограниченных ресурсах ИТ-инфраструктуры ЦОД, в таком случае одним из возможных решений может быть «расширение» во внешнее облако;
- скачки нагрузки на приложения, которые можно отрабатывать за счет перераспределения приложений между отдельными ЦОД или вывода нагрузки во внешнее облако. Случай похож на предыдущий с тем отличием, что после окончания пика приложение можно вернуть обратно, тем самым оптимизировав платежи внешнему провайдеру;
- миграция приложения вслед за источником/потребителем сервиса – интересный кейс, обретающий актуальность в эпоху «Интернета вещей» (IoT).
Во всех этих случаях приложение должно в автоматизированном режиме переехать из одного ЦОД в другой и перевезти с собой не только содержимое виртуальных или физических машин, но и свои сетевые компоненты, сетевые настройки. Причем с точки зрения пользователя порядок работы с приложением не должен меняться. Конечно, эти задачи в том или ином объеме решаются и сейчас, но только полностью реализованный программно-определяемый дата-центр позволит избежать всех ограничений. Как его построить? ИТ-архитектура ЦОД делится на 3 слоя:
- уровень вычислительной платформы, на котором работают программы. Он состоит из четырех подсистем: дисковой, серверной, сетевой (уровень доступа) и платформы виртуализации. Задача этого уровня заключается в полной поддержке процесса функционирования виртуальных и физических серверов. «Наверх» из этого уровня выходит набор виртуальных сетей с помещенными в них интерфейсами серверов;
- уровень сети дата-центра, на котором происходит сетевое взаимодействие и формирование «контейнеров» приложений. Его задачи – формирование приложений из отдельных серверов и виртуальных машин и добавление сетевых сервисов между ними;
- уровень границы дата-центра, его задачей является стыковка приложений с каналами (VPN, MPLS, Internet), через которые пользователи получают доступ к ним.
С уровнем вычислительных платформ все достаточно просто – происходившая последние 4–5 лет революция в подходе к их построению доказала преимущества использования конвергентных инфраструктур. На сегодняшний день их существует множество: либо ставшие уже традиционными FlexPod, VSPEX, vBlock, либо недавно присоединившиеся к ним VersaStack, UCP или UCSO. Вы просто берете одну из названных архитектур, ставите поверх нее требуемую платформу виртуализации, и все – можно разворачивать операционные системы. Используемый с этими инфраструктурами продукт управления Cisco UCS Director делает уровень вычислительной платформы полностью программно-определяемым.
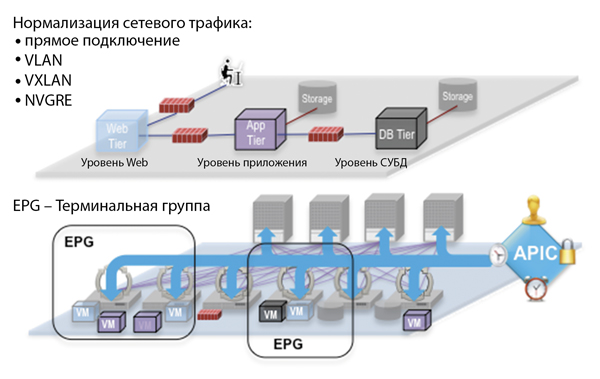
С уровнем сети дата-центра все гораздо сложнее. Как мы уже говорили выше, ни одна из существовавших до недавнего времени технологий не позволяла в полной мере решить задачу программной настройки сетевых функций приложения. Добавляла проблем и конкуренция, сложившаяся между производителями платформ виртуализации, ведь каждый из них использует даже собственный протокол инкапсуляции сетевого трафика для подключения к сети ЦОД (VXLAN у VMware, NVGRE у Microsoft и др.). При этом существующие приложения могут использовать разделение на VLAN’ы и даже прямое подключение к выделенному порту коммутатора. При традиционном подходе к настройке сети неизбежно появление границ ее возможностей. Для построения ядра сети дата-центра без подобных ограничений Cisco разработала архитектуру сети, ориентированную на приложения (Application Centric Infrastructure, ACI).
Архитектура ACI применяет модель политик для хранения сетевых настроек приложения, что позволяет автоматически распространять изменения на все устройства сети и, соответственно, сокращать время и ресурсы, необходимые для разворачивания приложений, более того, автоматизировать этот процесс. В архитектуре используется понятие терминальной группы (End Point Group, EPG) для описания портов виртуальных и физических машин, находящихся в одном сетевом сегменте. Далее между терминальными группами задаются правила прохождения сетевого трафика, таким образом строится сетевая модель приложения. Политики являются едиными для всей фабрики ACI, это еще одно понятие, описывающее группу коммутаторов, работающих по единым правилам, обычно это сетевое «ядро» дата-центра. Важно, что на входе в фабрику ACI весь сетевой трафик нормализуется, что дает возможность использовать в одной терминальной группе приложения, работающие в кластере VMware или Hyper-V и на традиционной архитектуре (включая физические серверы). Например, если вам необходимо произвести постепенную миграцию приложений в облако, вы можете подключить к одной фабрике ACI физические серверы и кластер виртуализации и переносить нагрузку постепенно с минимальными простоями и без значительных временных затрат на перенастройку сети.
Еще более интересный вариант использования решения заключается в обеспечении работы разных частей одного приложения (например, сервера приложений и СУБД) на разных платформах виртуализации. Ведь у гипервизоров могут различаться производительность, плотность размещения нагрузки, модель лицензирования. С архитектурой ACI администратор сможет выбирать, где ему размещать приложения, без оглядки на физическую сеть дата-центра и настройки конкретных единиц оборудования.
В случае облачной платформы, работающей поверх архитектуры ACI, управление фабрикой может быть интегрировано с тем же инструментом UCS Director, который используется для настройки вычислительной платформы. Это означает, что из одного и того же оркестратора мы можем настроить как вычислительную, так и сетевую части ЦОД. Это дает нам возможность говорить о полноценном управлении ЦОД из единого интерфейса или даже через единый API (UCS Director реализует "северный" REST API для интеграции с инструментами управления более высокого уровня).
Еще одним важным моментом во всей истории с ACI является то, что протоколы, используемые для конфигурирования фабрики, являются открытыми. Это позволяет сторонним компаниям свободно разрабатывать сетевые устройства, реализующие те или иные сетевые функции. Поэтому приложение, однажды настроенное для работы в архитектуре ACI, сможет перевести в другой ЦОД (например, при аварийном восстановлении) все свои сетевые политики и настройки.
Рис. 2. Концепция сети, ориентированной на приложения
Вместо заключения: следующий шаг – Интероблако
Что нам дает концепция программно-определяемого ЦОД, кроме повышенной гибкости в разворачивании и управлении приложениями? Современный мир – мир многих облаков, в том числе гибридных. Совершенно ясно, что практически ни одна компания не отдаст всю свою инфраструктуру в облако, однако многие уже перемещают в cloud-среды отдельные системы. Некоторые компании пользуются услугами нескольких облачных провайдеров, частных и публичных. Как обеспечить гибкость ИТ-инфраструктуры и одновременно сохранить контроль над ее безопасностью и надежностью работы? Не стоит забывать и об обстоятельствах глобального масштаба. Например, в нашей стране в ближайшее время вступят в силу поправки к закону о персональных данных, запрещающие хранить персональные данные россиян за границей. Закон по сути своей правильный, но как обеспечить его выполнение? Использование концепции сетевых политик приложения, заложенной в архитектуре ACI, позволяет переносить приложения из одного облака в другое и при этом сохранять всю их сетевую конфигурацию.
Рис. 3. Концепция Интероблака
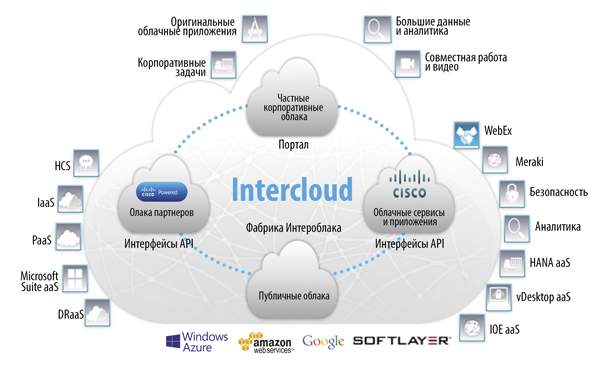
Логическим продолжением и дополнением к этому служит архитектура Интероблака, представленная Cisco совместно с партнерами. Это глобальная сеть облачных провайдеров, позволяющая создавать гибридные облака, осуществлять миграцию приложений из одного облака в другое и даже строить приложения, работающие в нескольких cloud’ах. Если рассмотреть пример с персональными данными более подробно, то глобальная компания может выделить персональные данные граждан России в отдельную БД, перенести сервер с этой БД в дата-центр российского облачного провайдера и тем самым удовлетворить требованиям законодательства. При этом с продуктом Intercloud Fabric миграция сервера и настройка канала могут быть выполнены в полуавтоматическом режиме (решение о начале миграции, конечно же, остается за человеком). И неважно, что внутри корпоративного дата-центра приложение работало на платформе VMware, а облачный провайдер использует, например, Azure Pack. ПО Intercloud Fabric for Business автоматически выполнит конвертацию формата виртуальной машины в тот, который используется в облачной платформе.
Таким образом, программно-определяемый ЦОД является необходимой платформой для реализации глобальной облачной среды, за которой стоит будущее информационных технологий.

