 Подписаться
Подписаться Читать в телеграм
Читать в телеграм

Шерлок Холмс: Но я-то не каждый, Ватсон, поймите: человеческий мозг — это пустой чердак, куда можно набить всё, что угодно. Человек тащит туда нужное и ненужное. И наконец наступает момент, когда самую необходимую вещь туда уже не запихнёшь. Или она запрятана так далеко, что ее не достанешь. Я же делаю всё по-другому. В моём чердаке только необходимые мне инструменты. Их много, но они в идеальном порядке и всегда под рукой. А лишнего хлама мне не нужно.
Художественный фильм «Шерлок Холмс и доктор Ватсон»
Допустим, мы определили проблему доступности приложения на стороне пользователя. При этом все контролируемые инфраструктурные метрики в норме. Как решить задачу обнаружения корневой причины недоступности? Типичный сценарий – подключение одного или нескольких экспертов, осуществляющих поиск причины вручную, методом анализа предыдущей практики, журнальных файлов, моделирования ситуации и пр.
Классические средства мониторинга вряд ли помогут на этом этапе – собираемые ими данные ограничены, фрагментарны. Обычно на мониторинг ставятся компоненты ИТ-систем, выход из строя которых можно предположить заранее: мы не можем контролировать все возможные аспекты работы приложения, поскольку ограничены возможностями вычислительной платформы и объемом хранимых данных. Кроме того, у классических систем ограничены функции корреляции собираемой информации. Полнофункциональные детальные сервисно-ресурсные модели, которые необходимы для анализа данных мониторинга, крайне сложны в сопровождении и часто не используются.
Следствием всего этого является потеря времени на поиск причин проблем, на анализ и сопоставление дополнительной информации. Но не все так плохо – развитие, появление новых технологий не только усложняет жизнь системам, но и обогащает их новыми инструментами. В нашей статье мы хотим сосредоточиться на одном из подобных примеров – применении методов работы с Большими Данными в средствах мониторинга ИТ.
Для начала необходимо определиться с терминами. С появлением технологии анализа Big Data в жизнь профессионального сообщества вошло новое понятие – Operations Intelligence (OI). Это класс аналитических решений, обеспечивающих комплексную обработку и визуализацию данных (значений параметров, потоков событий, бизнес-операций) из различных источников в режиме, близком к реальному времени.
Основные характеристики OI-систем:
- мониторинг, обнаружение событий и визуализация информации в режиме, близком к реальному времени;
- многомерный анализ данных: выявление корневых причин; анализ временных рядов и прогнозирование;
- использование технологий анализа Big Data.
Системы OI многокомпонентны: за рамками нашей статьи останутся обработка сложных событий (Complex Event Processing), мониторинг бизнес-операций (Business Activity Monitoring) и др. Сосредоточимся на основных технологических решениях, обеспечивающих совместный оперативный анализ данных различных типов (временные ряды, текстовые события и т.д.). Специализированных игроков на данном рынке пока немного – это слишком молодая технология, требующая достаточно больших вложений в ее разработку и развитие. В качестве примера можно назвать решения, предлагаемые компаниями Splunk, Hewlett-Packard, IBM. Их общая черта – применение компонентов анализа Big Data в мониторинге ИТ.
Отметим, что решения класса IT Operations Analytics не являются заменой оперативных средств мониторинга, сообщающих нам о явных и конкретных сбоях. Их место – над этими системами. Они являются инструментом аналитика, работающего с проблемами, но могут применяться и в операционном мониторинге.
Как уже было сказано, с момента создания систем мониторинга как класса программных решений и вплоть до сегодняшнего дня мы жили в условиях ограничения вычислительной мощности используемых платформ. Для оперативного мониторинга выбирались только те данные, влияние которых на целевую функцию контролируемой системы было понятно и известно. Попытки сбора и обработки всей доступной информации приводили к существенному увеличению времени анализа, т.е. фактически переводили систему в раздел offline-аналитики, а это, в свою очередь, нивелировало смысл её создания. В итоге мы получали ограниченное решение, позволяющее выявить и, возможно, отранжировать по значимости потенциальные причины возникновения проблем. Далее был необходим глубокий ручной анализ журнальных файлов, сочетания нетипичных показателей и др.
Итак, что же изменилось? Ряд разработчиков, исторически или унаследованно занимавшихся технологиями анализа и обработки, обратили внимание на схожесть задач мониторинга и анализа Big Data (разные данные, большие объемы, требования к скорости). В результате были созданы системы нового типа – IT Operations Analytics. В качестве примера рассмотрим решение от компании Hewlett-Packard. Его основой являются два технологических компонента компании HP – аналитическая база данных HP Vertica и ПО управления журналами HP ArcSight. Обобщенная архитектура решения представлена на рис. 1.
Рис. 1. Архитектура системы HP Operations Analytics
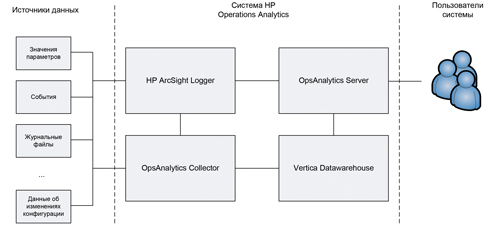
Состав решения:
- OpsAnalytics Collector, обеспечивающий сбор данных из различных источников.
В их роли выступают:
- файлы CSV;
- ПО мониторинга компании HP: HP SiteScope, HP Operations Manager и OMi, HP BPM и др.;
- средства мониторинга журнальных файлов: HP Arc-Sight Logger (входящий в состав решения) и Splunk;
- HP ArcSight Logger, отвечающий за анализ журнальных файлов по различным принципам и предоставление структурированной информации в OpsAnalytics Collector (результаты мониторинга), а также, по запросу, серверу OpsAnalytics Server (в «сыром» виде при выполнении пользователями системы соответствующих поисков);
- HP Vertica Datawarehouse – БД, обеспечивающая долговременное хранение данных в виде, адаптированном к выполнению аналитических запросов различного типа. Стоит отметить, что эти данные сжаты, в результате чего обеспечивается ощутимая экономия дискового пространства по сравнению с традиционными базами данных;
- OpsAnalytics Server – модуль, отвечающий за предоставление функций HP Operations Analytics пользователям системы.
В соответствии с объемом предполагаемой к обработке информации компоненты решения могут масштабироваться на несколько узлов: новые могут быть добавлены по мере роста объема данных и количества выполняемых аналитических запросов.
Предоставляемый функционал включает в себя несколько основных блоков: поиск информации по различным критериям, визуальную и прогнозную аналитику, а также анализ журнальных файлов.
Визуально интерфейс пользователя представляет собой настраиваемый под конкретные задачи портал. Он может формировать состав представлений в процессе выполнения анализа и сохранять их для последующей работы. Одной из интересных особенностей решения является наличие так называемой «машины времени» (Time maсhine). С ее помощью можно оперативно получать требуемую информацию за заданный период времени без необходимости выполнения последовательных выборок для каждого блока данных. «Машина времени» примененяется одновременно для всех выводимых на экран метрик и событий. Наличие подобной функции позволяет «на лету» выполнять совместный анализ необходимых данных.
Рис. 2. Интерфейс системы
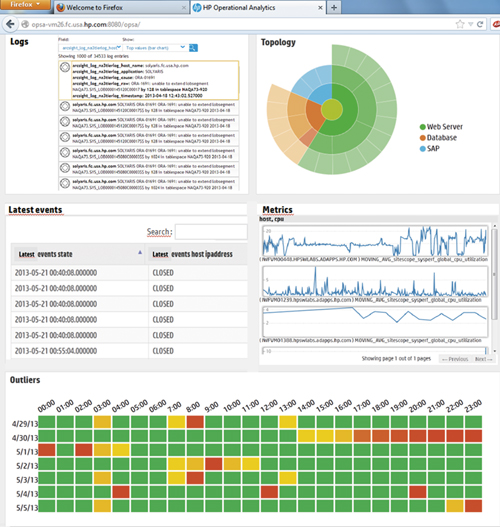
В системе реализован поиск по различным контекстам. Например, можно одновременно выполнять выборки по большому количеству критериев: по приложению (с учётом топологии, полученной из внешних источников), серверу, географическому положению элементов инфраструктуры и т.д. Например, можно находить причины проблем в работе банкоматов за счет совместного анализа данных об их доступности, о работе сети передачи данных и изменениях погоды.
На основе метрик, собранных в базе данных HP Vertica Datawarehouse строятся прогнозы изменения их значений и визуализируются отклонения от нормальных значений за заданный период (baseline).
Возможности модуля HP ArcSight Logger по анализу журнальных файлов достаточно хорошо известны. Ключевой особенностью его применения в составе HP Operations Analytics является превращение неструктурированных или слабоструктурированных данных в измеряемые метрики, доступные для совместного анализа с метриками доступности и производительности.
Отметим, что с точки зрения «чистых» функций (поиск, прогнозирование, визуализация сводной информации) система не несет в себе ничего нового. Все эти задачи так или иначе решаются в большинстве классических средств мониторинга. Ключевые отличия систем, вобравших в себя опыт работы с Большими Данными, – возможность хранения огромного количества данных и высокая скорость выполнения аналитических запросов. Ранее анализ работы распределенного приложения занимал часы и дни, был связан с обработкой десятков тысяч событий и записей в журналах, значений сотен метрик. Теперь – с использованием технологий анализа Big Data – эти операции можно выполнять практически в реальном времени.

