 Подписаться
Подписаться Читать в телеграм
Читать в телеграм

Один из основателей компании Бьёрн Берг предложил использовать систему цветового кодирования информации. Зеленым цветом выделялись текущие фильтры, белым – значения, связанные с текущим выбором, а серым – несвязанные значения. Эти цвета легли в основу работы ассоциативной (связанной) модели данных – запатентованной технологии QlikTech, благодаря которой каждый пользователь может самостоятельно, без глубоких математических знаний исследовать бизнес-информацию, загруженную в QlikView.
Очень часто нам задают вопрос: «А чем вы отличаетесь от других продуктов?». На него у нас есть два ответа. Все зависит, от того, кто спрашивает. Для сотрудников ИТ-служб важно понимать технологические отличия, сильные и слабые стороны QlikView и политику ценообразования. Бизнес-пользователям важно знать функциональные возможности системы, то есть насколько быстро и правильно QlikView сможет решить их задачи, кто уже использует продукт в их отрасли и насколько быстро происходит возврат вложенных в проект денежных средств. Я постараюсь ответить на обе категории вопросов в этой статье.
Немного статистики
В 2010 году мы начали бизнес-исследование проектов наших клиентов. На тот момент у QlikTech было около 22 000 клиентов по всему миру, а в России только-только стартовали активные Enterprise-продажи. Результат исследования был опубликован на нашем сайте, а информация загружена и представлена в QlikView. В этом мы довольно уникальны: в QlikTech вообще вся аналитика и отчетность построена в QlikView и доступна менеджерам в любой момент времени с любого мобильного или стационарного устройства. Исследование было сегментировано по отраслям и подотраслям, бизнес-задачам и категориям сотрудников. Всего были опрошены более 1000 клиентов среднего и крупного бизнеса. Я не буду вдаваться в детали этого исследования, приведу среднюю статистику проектов.
В 77% случаев длительность промышленного проекта – от создания технического задания до запуска в эксплуатацию – не превышала 3 месяцев. Из них около 48% были реализованы в течение 1 месяца. В среднем каждый вложенный рубль (доллар) через 198 рабочих дней увеличивался в 1,86 раза (ROI = 186%). Совокупная стоимость владения решением была в среднем на 53% ниже, чем стоимость решений от других вендоров, которых рассматривал клиент. Три основные причины выбора продукта: быстрота разработки и развертывания решения; простота работы в системе для конечных пользователей; простота и удобство в разработке и поддержке решения. Интересен момент, связанный со стоимостью. На последнем месте по значимости стояла стоимость внедрения. То есть если критерий № 1 имел вес в 49% у 589 респондентов, то критерий стоимости получил всего 2%.
Из чего складывался такой эффект? 331 респондент отметил, что в среднем производительность труда повысилась на 34%. Например, после внедрения QlikView в компании Hypotheekshop (ведущий ипотечный консультант Голландии, 180 офисов, 15 000 клиентов) 90% всех клиентских запросов обрабатываются в течение одного рабочего дня. Это, в свою очередь, на 30% повысило уровень клиентской конверсии. На 10% были сокращены операционные затраты. Время подготовки отчетности уменьшено вдвое. Другой пример: Swedbank окупил решение для 5000 пользователей за 6 месяцев. Построена детальная аналитика по 4,3 млн клиентов банка.
«QlikView – это чрезвычайно мощная платформа класса Business Discovery. Решение дает пользователям возможность получить доступ к данным и свободно их анализировать. Это позволяет им подняться по «лестнице знаний» от уровня сырых данных до точной информации, которую можно использовать для анализа, выводов и принимать соответствующие действия», – делится опытом Анки Арнелл, начальник отдела маркетинга и онлайн-банкинга, Swedbank.
196 респондентов отметили 20%-ное снижение операционных затрат и 16%-ное повышение выручки. Так, за 4 года решение по управлению рисками принесло компании Dakotacare (сфера медицинского страхования) дополнительно 1,4 млн долларов США. Национальная служба здравоохранения Великобритании за два года сэкономила 66 млн долларов за счет анализа закупок с помощью QlikView. Теперь предлагаю непосредственно перейти к распространенным мифам о QlikView и их развенчиванию.
Миф первый: они все хранят в памяти, и им нужны мощные серверы
Действительно, исходя из названия технологии многие ИТ-специалисты делают вывод, что построенная модель данных находится в оперативной памяти и для ее обновления системе нужно каждый раз обращаться к источнику. Если вдруг сервер «упал», информация в системе потеряна и нужно загружать ее заново. Если информации много, для ее обработки нужен очень мощный сервер, а, может быть, и несколько. Таким образом, у продукта есть скрытая затрата в виде очень высокой аппаратной стоимости. Но это заблуждение.
После построения скелета загрузочной модели во внутреннем ETL-средстве (Extract, Transform, Load – инструмент для выгрузки, трансформации данных и их загрузки в подсистему хранения) производится загрузка информации в ассоциативную (связанную) модель данных. Для этого QlikView обращается к источникам данных и в режиме параллельной загрузки (используется мощность всех доступных ядер сервера) формирует набор плоских таблиц. Система строит между ними автоматические связи по принципу «одинаковые поля с одинаковыми полями» и производит нормализацию данных. Теперь информация хранится в оперативной памяти в плоских связанных таблицах. В каждой из них находятся только уникальные значения, по дубликатам QlikView хранит небольшие ссылки, на основании которых можно восстановить логику связей. Каждый объект информации связан с любым другим объектом, поэтому можно отследить любую зависимость. При формировании связанной модели срабатывает «движок» компрессии данных. Чем больше дубликатов, тем выше компрессия. Например, у вас есть информация о годовых продажах (несколько показателей) на каждый день по 2000 торговых точек. В простой плоской таблице одну и ту же торговую точку можно будет встретить 365 раз, в QlikView – только один. Таким образом, сотни гигабайт информации из источника превращаются в десятки на уровне QlikView.
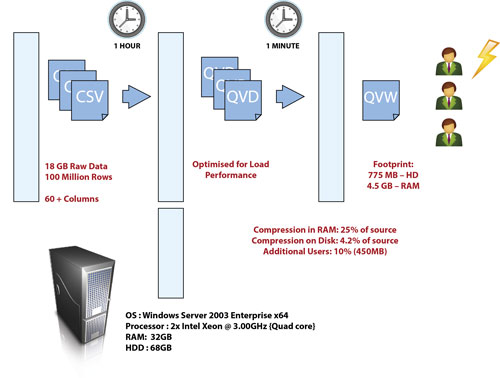
После формирования модели данных в оперативной памяти QlikView сохраняет дубликат информации на жестком диске в своем формате. Для работы с системой не требуется построение специализированного хранилища данных, соответственно, не нужна установка отдельной СУБД стороннего производителя. При развертывании сохраненной модели в оперативной памяти происходит ее увеличение, но не до первоначального размера. В среднем в 4–5 раз. То есть если в вашем источнике данных объем информации для обработки занимает 300 ГБ, в идеальном случае модель на жестком диске займет около 10 ГБ, а в оперативной памяти сервера – около 40–50 ГБ. Более точный расчет проводится по специальной модели расчета сайзинга. Эта процедура отработана и является типовой в арсенале нашего партнера. В 2011 году специально для российских заказчиков наш партнер – компания «Инфосистемы Джет» – провел нагрузочное тестирование QlikView. Формулу в очередной раз подтвердили на практике, а показатели по объемам обрабатываемой информации были выше ожидаемых.
На проектах происходят и более интересные случаи. Например, два года назад для одной российской розничной сети строилось приложение по 9 ключевым показателям деятельности компании (средний чек, % маржи, стоимость квадратного метра, средняя зарплата и т.п.). Все показатели сводились по 5 временным критериям (год, месяц, неделя и т.п.), причем самым нижним уровнем была неделя, а аналитика собиралась по 200 торговым точкам. В результате сжатия информации итоговая информационная панель и модель данных занимали менее одного мегабайта. На уровне источника данных находилось около 30 млн записей по чекам, а вся информация собиралась за 3 года. До запуска этого проекта ИТ-служба запланировала покупку небольшого 4-ядерного сервера со 128 ГБ оперативной памяти. На этом сервере сегодня работает несколько моделей QlikView, обслуживая до 100 одновременных подключений.
Миф второй: они не могут предоставить сервис для тысяч пользователей
Эту точку зрения мы стали слышать все реже и реже. Но еще в 2010 году, когда в России все только начиналось, об этом говорили повсюду.
Для организации работы тысяч пользователей QlikView умеет управлять кластером серверов, осуществлять балансировку нагрузки и делает всё это незаметно для сотрудников компании. В 2012 году в США для одной автостраховой компании был запущен проект на 27 000 активных пользователей QlikView. Для организации правильной работы системы была разработана архитектура из 100 enterprise-серверов, которая поддерживалась другой сотней тестовых серверов и управлялась двумя сотнями Publisher (специальный продукт QlikView для работы с большими моделями данных, для построения кластеров и создания сложных ролевых моделей безопасности). Кластеры создавались на уровне дивизионов и консолидировались на уровне головной компании. Архитектура обеспечивала бесперебойную работу приложений в режиме 24х7. Общий объем анализируемой информации имеет символ ТБ после цифр.
Другой пример: Swedbank за 6 месяцев создал и развернул решения для коммерческого блока, блока маркетинга и ИТ-службы, которыми пользуются более 5000 пользователей. Источником данных является хранилище, построенное на продуктах Terradata, в которое стекается информация из сотни транзакционных систем. До построения решения 315 офисов пользовались электронными таблицами и тратили много времени на их формирование и перепроверку. В этом проекте активное участие принял наш R&D (Research & Development) центр, который развернул результаты пилотного проекта на своих мощностях и на практике показал, как будет происходить масштабирование числа пользователей.
С 2012 года такие эксперименты можно ставить и в России. «Инфосистемы Джет» – первый наш партнер в России, который на своих мощностях провел нагрузочные испытания QlikView и создал технологический стенд. Результаты его работы были отправлены в наш R&D центр города Лунд для более детального изучения. Стратегическая цель компании QlikTech – 1 миллиард пользователей. Для немассового продукта довольно амбициозно, но мы уверены, что эта цифра достижима. Наши центры исследований и разработок постоянно совершенствуют технологию QlikView. Мы всегда стараемся получить обратную связь от наших клиентов? А наиболее интересные идеи включаются в план развития.
В прошлом году в рамках выхода новой, 11-й версии продукта была реализована технология организации сессий совместной работы. Теперь бизнес-пользователь может создать специальную ссылку и отправить ее своим коллегам. При переходе по ссылке сотрудник компании без выданной активной лицензии получает доступ к текущей сессии (открытому приложению QlikView), и с этого момента начинается интерактивная работа сотрудников. Приложение становится общим, и каждый пользователь сессии может взять управление на себя. Каждый клик будет отработан системой, и QlikView даст нужный ответ. ( Как это работает? Просто зайдите на www.demo.qlikview.ru и запустите любой пример. Для активации сессии необходимо нажать на кнопку share session.) С выходом этой функциональности мы убрали понятие «конечный пользователь». У некоторых наших клиентов число пользователей QlikView выросло в несколько раз.
Рис. 1. Пример построения сложной кластерной архитектуры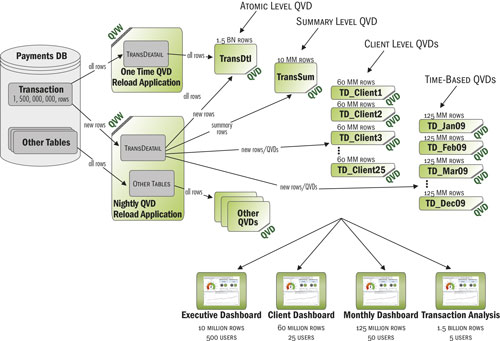
Миф третий: они медлительны и не умеют работать с метаданными
На нашем сайте есть возможность скачать бесплатную персональную версию, с помощью которой можно разработать приложение и использовать его на персональном компьютере. Но немногие новички знают, что не всегда правильно загружать информацию в QlikView в один этап (построение однозвенной архитектуры). У системы существует специальная контейнерная технология хранения информации (QlikView Data File, QVD), а если возникают задачи управления версиями, очистки данных, построения сложных загрузочных схем и т.д., у нее есть специальный отдельный ETL-модуль – Expressor.
На больших проектах, как правило, строится трехзвенная архитектура. Первоначальную информацию из источника выгружают в QVD-контейнеры, далее ее из первой линии контейнеров перегружают с необходимой трансформацией во вторую. Итоговые приложения могут быть построены на базе обеих линий. Зачем же нужны эти QVD-контейнеры?
Первая задача – убрать нагрузку с транзакционной системы, чтобы минимизировать риск сбоя и снижения производительности по вине стороннего софта. Вторая – повысить скорость загрузки информации. Для QlikView QVD – это родной формат, с которым она работает на порядок быстрее. И третья задача – создание последующей инкрементальной загрузки информации, когда к модели будет подгружаться только измененная и новая информация из источников. Таким образом, создается промежуточный слой данных, с которым разработчик может проводить необходимые преобразования.
Рис. 2. Принцип работы промежуточного слоя данных
Далее возникает следующая задача – организация модели данных. Их нужно несколько или всё в одной? Чтобы ответить на этот вопрос, необходимо знать, какое число пользователей системы и с какой информацией будет работать. У нас есть несколько технологий оптимизации, которые направлены на снижение требований к серверу (-ам). Чаще всего используется технология «цепочки документов», когда есть несколько уровней приложений. Верхний уровень, построенный на высоких агрегатах, с которым работают все. Средний – с ним работают специалисты по направлениям в соответствии с ролевой моделью. И нижний – работают единицы сотрудников при необходимости, здесь располагаются детальные транзакции. Переход с уровня на уровень абсолютно не заметен для пользователя. Но с точки зрения работы сервера экономится значительный объем оперативной памяти.
Рис. 3. Пример разделения модели данных с использованием технологии цепочки документов
Если объем данных в источнике очень большой (терабайты/петабайты), а для анализа требуется организация среза данных на основании параметров запроса пользователя, стоит обратить внимание на новую технологию QlikView – Direct Discovery. Это прямое обращение к источнику данных с онлайн дозагрузкой информации к модели. Технология была представлена в декабре 2012 года, но уже многие наши клиенты ощутили преимущества ее использования.
Заключение
Осенью 2013 года в Москве состоится ежегодная конференция QlikView, на которой будет представлена принципиально новая версия продукта – QlikView 12. Сейчас одним из трендов является удобная работа на мобильных устройствах, доступ к необходимой информации в любой момент времени. Надеюсь, что мы сможем в очередной раз удивить наших пользователей.

